Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
10.3.2
-
ubuntu 16.0.2
-
10.0.34
Description
Hi Sergey,
While testing the performance of complex queries I see huge degradation in performance as we increase the number of client threads. I used the benchamark mysqlslap to evalaute the complex queries.
Background of tables: Two tables populated with 4096 records populated and a common column is populated which helps in joining the two tables.
Sample mysqslap command uses:
mysqlslap -uroot --concurrency=24 --create-schema=test --no-drop --number-of-queries=500 --iterations=10 --query='select count(*), category from task inner join incident on task.sys_id=incident.sys_id group by incident.category' –p
|
Sample output : The above command runs for 24 threads for the total number of queries of 500 .It runs 10 times the same operation . Number of clients running queries: 24 Average number of queries per client: 20
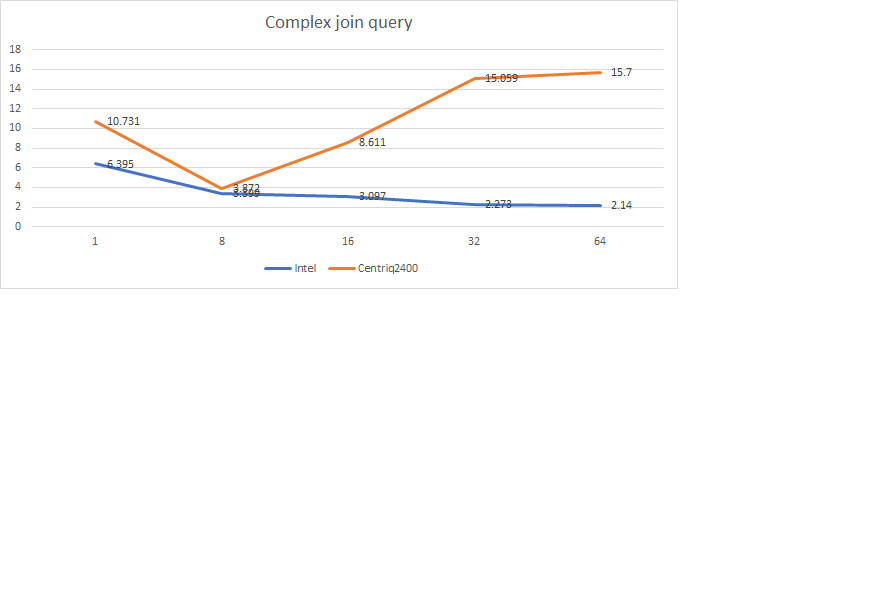
Attached is the time take for each combination of threads tested in secs. Example 1 ,8 16 threads etc
On profiling I see atomic operations such as cmpxchg is the hottest function
Arm platform :
│ MY_MEMORY_ORDER_RELAXED);
|
│ while (lock_copy > threshold) {
|
0.00 │ ↓ b.le a0cf14 <pfs_rw_lock_s_lock_func(rw_lock_t*, unsigned long, char const*, unsigned int) [clone .constprop.112]+0x1
|
│ if (my_atomic_cas32_strong_explicit(&lock->lock_word,
|
0.04 │ ldr w2, [x29,#80]
|
8.68 │ f0: ldaxr w0, [x19]
|
0.00 │ cmp w0, w2
|
0.01 │ ↓ b.ne a0cefc <pfs_rw_lock_s_lock_func(rw_lock_t*, unsigned long, char const*, unsigned int) [clone .constprop.112]+0x1
|
88.19 │ stxr w3, w1, [x19]
|
0.00 │ ↑ cbnz f0
|
2.29 │104: ↑ b.ne a0ced4 <pfs_rw_lock_s_lock_func(rw_lock_t*, unsigned long, char const*, unsigned int) [clone .constprop.112]+0xd
|
│ rw_lock_s_lock_low():
|
|
|
Samples: 15M of event 'cycles:ppp', Event count (approx.): 9845312975908
|
Overhead Command Shared Object Symbol ◆
|
32.58% mysqld mysqld [.] pfs_rw_lock_s_lock_func ▒
|
26.85% mysqld mysqld [.] row_search_mvcc ▒
|
18.42% mysqld mysqld [.] pfs_rw_lock_s_unlock_func ▒
|
11.13% mysqld mysqld [.] pfs_rw_lock_s_unlock_func
|
I tired to relax the memory orderfrom seq_cst to acq_/relaxed caused a ldaxr/stlxr => ldaxr/stxr but not much benefit availed
Basically these are Low-level function which tries to lock an rw-lock in s-mode. Performs no
spinning.
In Intel I don’t see the function very hot
0.02% mysqld mysqld [.] pfs_rw_lock_s_lock_func ▒
|
0.02% mysqld mysqld [.] buf_page_get_gen ▒
|
0.02% mysqld mysqld [.] page_cur_search_with_match_bytes ▒
|
0.02% mysqld mysqld [.] row_search_mvcc ▒
|
0.02% mysqld mysqld [.] pfs_rw_lock_s_lock_fun
|
Can we do away with atomic operation since this being select queries?If not why cant we include spinning/pause in every lock function we try to acquire?
Sample code path
rw_lock_lock_word_decr(
|
/*===================*/
|
rw_lock_t* lock, /*!< in/out: rw-lock */
|
ulint amount, /*!< in: amount to decrement */
|
lint threshold) /*!< in: threshold of judgement */
|
{
|
#ifdef INNODB_RW_LOCKS_USE_ATOMICS
|
lint local_lock_word;
|
|
os_rmb;
|
local_lock_word = lock->lock_word;
|
while (local_lock_word > threshold) {
|
if (os_compare_and_swap_lint(&lock->lock_word,
|
local_lock_word,
|
local_lock_word - amount)) {
|
return(true);
|
}
|
local_lock_word = lock->lock_word;
|
}
|
return(false);
|
Attachments
Issue Links
- is blocked by
-
-
- Closed
-
- is part of
-
MDEV-14442 Optimization for ARM64 platform.
-
- Open
-
- relates to
-
-
- Closed
-
-
-

- Closed
-