Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Not a Bug
-
10.0.25, 10.1.14
-
Ubuntu x86_64
-
10.0.26, 10.0.28, 5.5.55, 10.0.30
Description
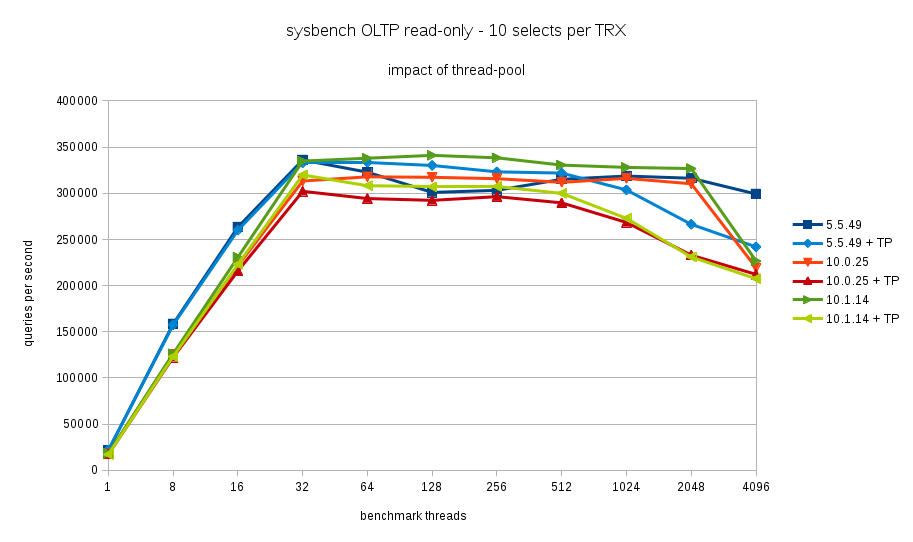
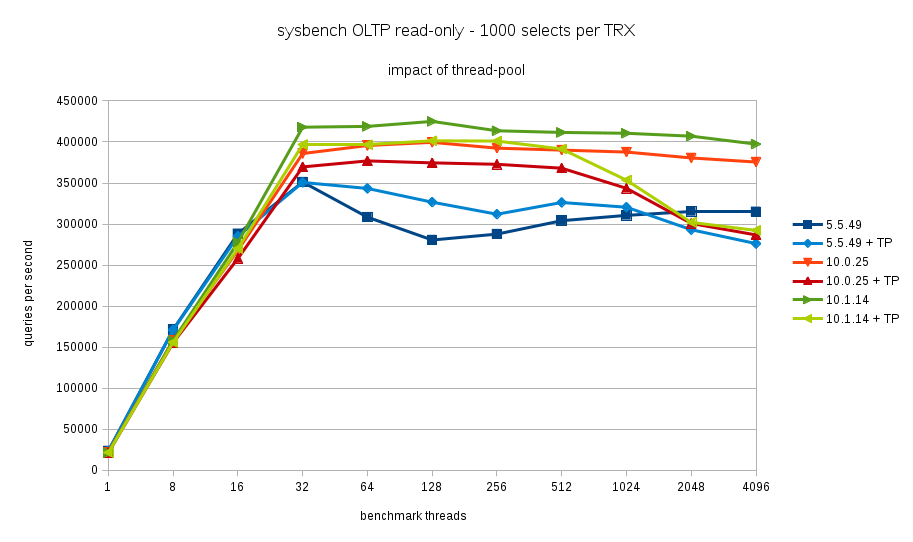
Enabling the thread pool leads to about 5% performance loss in MariaDB 10.0 and 10.1, but not in MariaDB 5.5. I tested 5.5.49 vs. 10.0.25 vs. 10.1.14.
The benchmark is sysbench OLTP read-only with 1000 point-selects per transaction. The benchmark machine has 16 cores (32 hyperthreads).
my.cnf:
[mysqld]
|
max_connections = 1300
|
table_open_cache = 2600
|
query_cache_type = 0
|
|
|
innodb_buffer_pool_size = 512M
|
innodb_buffer_pool_instances = 10
|
innodb_adaptive_hash_index_partitions = 20
|
|
|
thread_handling=pool-of-threads
|
See attached spread sheet for numbers.