Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Fixed
-
23.02.4
-
None
-
None
-
2025-4, 2026-2
Description
On a single-node MariaDB Columnstore instance, a query combining a LIKE pattern with a bitwise AND filter on a column (sig) is significantly slower than expected, despite each condition being fast when executed individually.
Table
- molecole with 167,772,160 rows
- sig is a BIGINT (64-bit), used to store Bloom filters
- smiles is a TEXT column storing molecular strings
- The data is highly duplicated (10 unique records repeated)
Queries and Performance
Fast (~1 sec):
SELECT count(*) FROM molecole
|
WHERE smiles LIKE '%C(=O)C(O)=C(C4=O)O)O[%' AND sig = 18373419839315247039; |
Slow (~5 sec):
SELECT count(*) FROM molecole
|
WHERE smiles LIKE '%C(=O)C(O)=C(C4=O)O)O[%' AND (sig & @mask) = @mask; |
Fast (~1 sec):
SELECT count(*) FROM molecole
|
WHERE (sig & @mask) = @mask; |
Key Observations
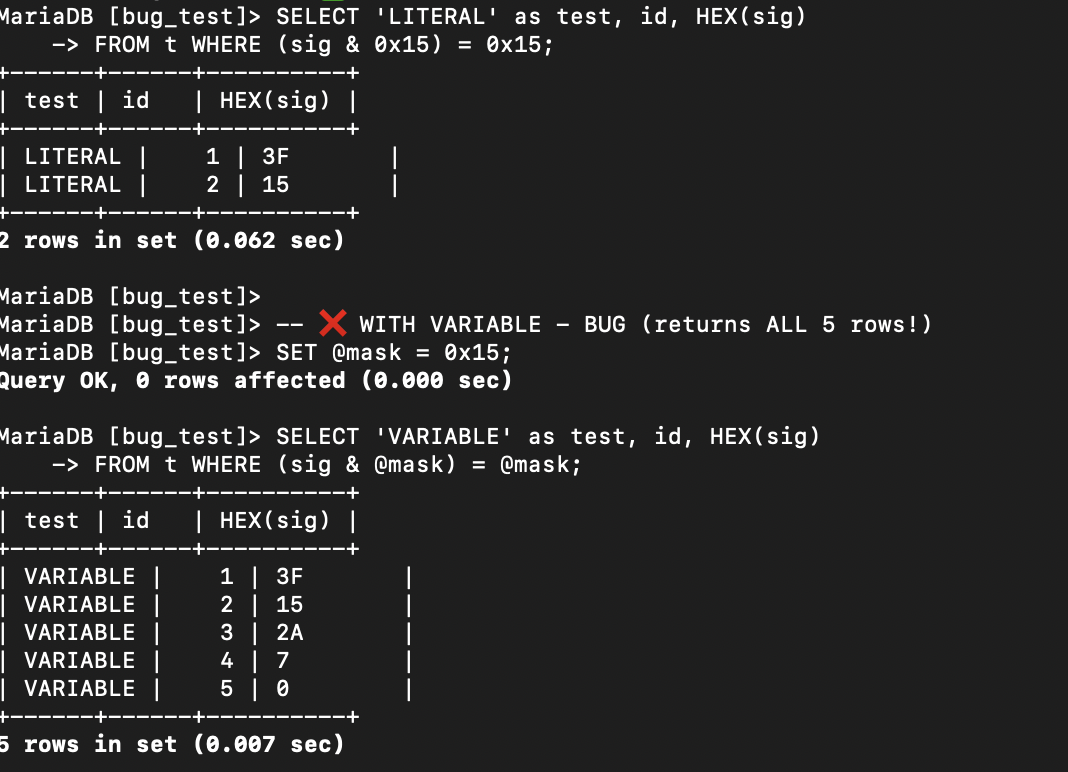
(sig & @mask) = @mask alone is fast and behaves as expected.
The combination with LIKE causes the bit operation to seemingly not pre-filter, leading to full evaluation of the LIKE for every record.
This negates the expected performance gain from short-circuiting evaluation or extent elimination.
This leads to the following deduction:
- The LIKE pattern, when executed only on the subset of rows that pass the equality filter (sig = ...), takes ~1 second, meaning it is not inherently expensive on the matched rows.
- The bitwise operation alone is also ~1 second, proving it is not computationally expensive.
- Therefore, the combined query should not take more than ~2 seconds in a naive worst-case additive model, assuming the optimizer uses the bitwise condition to filter early and apply LIKE only to the remaining subset.
However, in practice it takes ~4.87 seconds, which suggests: - The optimizer is not applying the bitwise filter first, or
- It is not using it to pre-filter the data before applying the expensive LIKE, thus, it ends up evaluating LIKE on a much larger dataset, defeating the filtering benefit of (sig & @mask) = @mask.
Conclusion
The optimizer appears to treat (sig & @mask) = @mask as a non-SARGable expression when combined with LIKE, preventing extent elimination and even early filtering. This seems to result in an unnecessary full scan + evaluation of the LIKE pattern.
Attaching the SQL code to replicate the environment and execution times
Attachments
Issue Links
- relates to
-
MCOL-4935 A prototype planner/optimizer using term rewriting
-

- Open
-