Details
-
Bug
-
Status: Closed (View Workflow)
-
 Minor
Minor
-
Resolution: Fixed
-
23.08.4
-
Ubuntu 22.04
Description
When a server is lagging behind and readwritesplit is configured with max_replication_lag, it will stop routing read queries to it but it will leave the connections open and it will continue to route session commands to them. This is done in the hopes that the replication lag will eventually subside and that the connections can be used again.
If the server is lagging behind by a lot (e.g. by several hours or even days), keeping the connection open is somewhat wasteful and, if nothing else, slightly misleading as it implies that it might be used for routing. A better alternative to this would be to discard connections to servers that are lagging behind by some amount.
Original description:
I have configured the following parameters in my Read-Write-Service:
max_replication_lag = 30000ms
|
causal_reads = global
|
causal_reads_timeout = 10000ms
|
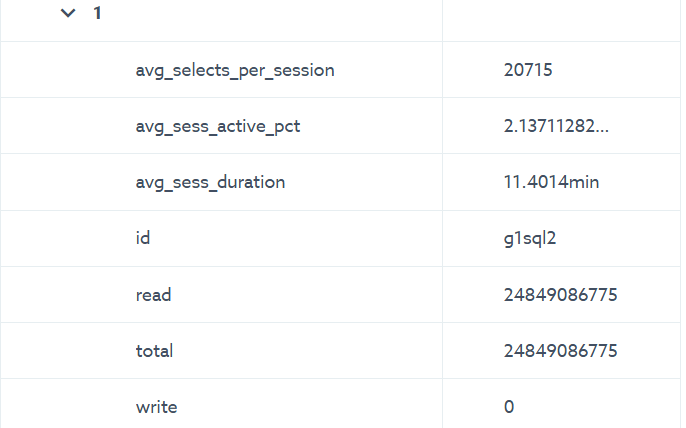
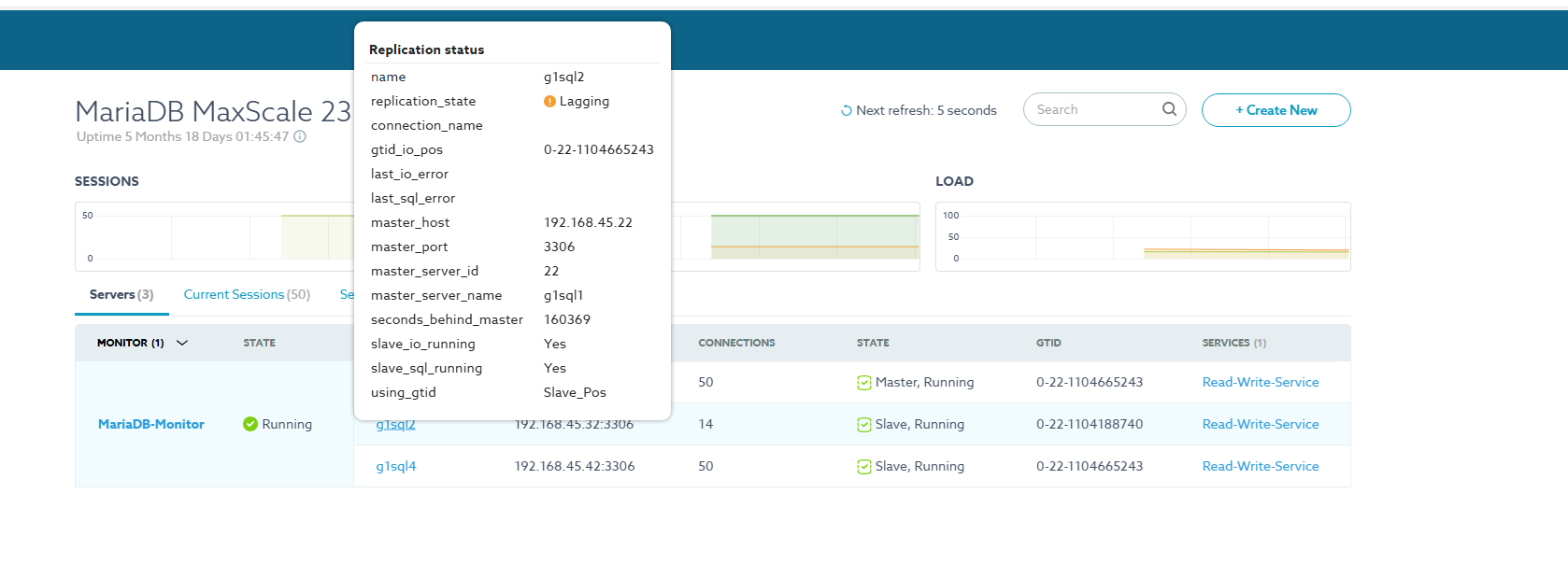
I notice if a replica server has been down for quite a long time, that on startup, the MariaDB-Monitor service must have a delay in reporting the actual replication lag, which results in the Read-Write-Service routing connections to the lagging replica..
The replica in question was ~140,000s behind, and I clearly don't want that to be added as a suitable server to connect to.
Is there:
1) A way to delay the initial routing until a valid replication lag has been identified?
2) A way to kill connections that are part of a lagging server automatically, once they've already snuck through?