Details
-
New Feature
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
Description
Storing binlog in InnoDB
I am in the final stages of a project to implement a new binlog
format that is managed transactionally by InnoDB. This is a complex change,
and I want to solicit comments early, so I encourage feedback.
The TLDR; of this:
- The current binlog format stores events separately from InnoDB. This
requires a complex and very constly 2-phase commit protocol between the
binlog and InnoDB for every commit. - The binlog format is rather naive, and not well suited as a
high-performance transactional log. It exposes internal implementation
detail to the slaves, and its flat-file nature makes it inflexible to
read (for example finding the last event sequential start from the
start). Replacing it with something new has the potential to reap many
benefits. - This project proposes to extend the storage engine API to allow an engine
to implement binlog storage. It will be implemented in InnoDB so that
binlog events are stored in InnoDB tablespaces, and the standard InnoDB
transactional and recovery mechanisms are used to provide crash safety
and optionally durability. - This mechanism will allow full crash-recovery and consistency without any
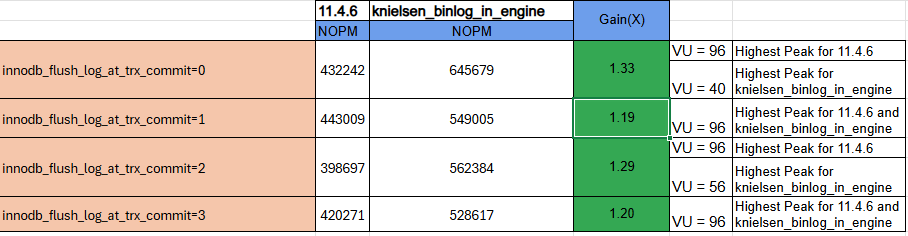
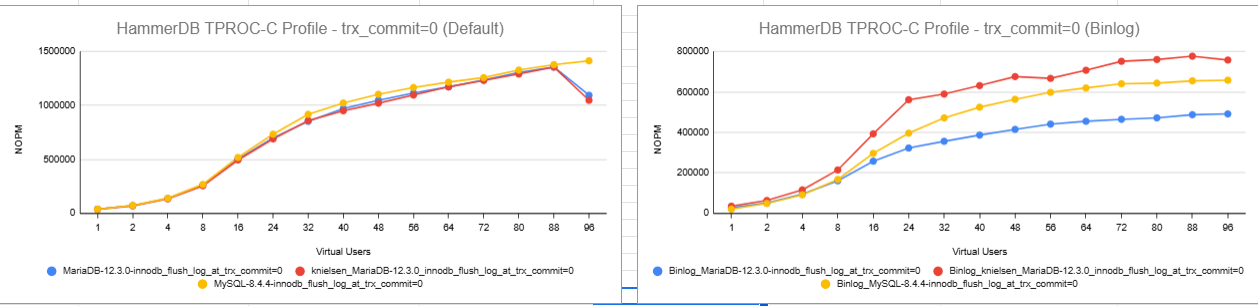
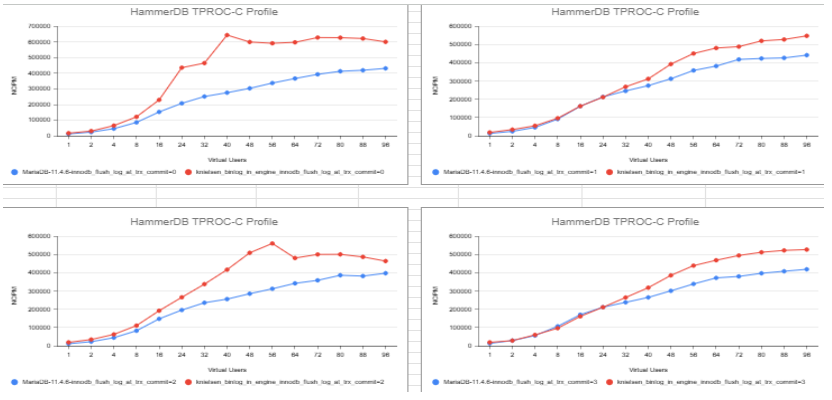
fsync per commit (--innodb-flush-log-at-trx-commit=0), providing huge
improvement in throughput for applications that do not require strict
durability requirements. And it will reduce fsync requirement to one per
commit for durable config, with greatly improved opportunities for group
commit.
Code for a prototype implementation is developed in the branch knielsen_binlog_in_engine:
https://github.com/MariaDB/server/commits/knielsen_binlog_in_engine
User-level documentation
This document describes the new binlog implementation that is enabled using
the --binlog-storage-engine option.
The new binlog uses a more efficient on-disk format that is integrated with
the InnoDB write-ahead log. This provides two main benefits:
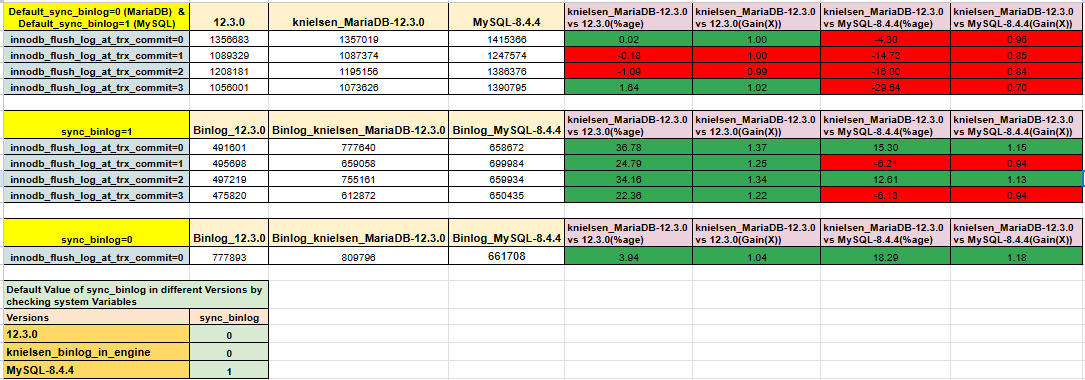
- The binlog will always be recovered into a consistent state after a crash. This makes it possible to use the options --innodb-flush-log-at-trx-commit=0 or --innodb-flush-log-at-trx-commit=2, which can give a huge performance improvement depending on disk speed and transaction concurrency.
- When using the option --innodb-flush-log-at-trx-commit=1, commits are more efficient since there is no expensive two-phase commit between the binlog and the InnoDB storage engine.
Using the new binlog
To use the new binlog, configure the server with the following two options:
- log_bin
- binlog_storage_engine=innodb
- Note that the log_bin option must be specified like that, without any argument; the option is not an on-off-switch.
Optionally, the directory in which to store binlog files can be specified with binlog_directory=<DIR>. By default, the data directory is used.
Note that using the new binlog is mutually exclusive with the traditional binlog format. Configuring an existing server to use the new binlog format will effectively ignore any old binlog files. This limitation may be relaxed in a future version of MariaDB.
Replicating with the new binlog
Configuration of replication from a master using the new binlog is done in the usual way. Slaves must be configured to use Global Transaction ID (GTID) to connect to the master (this is the default). The old filename/offset-based replication position is not available when using the new binlog implementation on the master.
Working with the binlog files
The binlog files will be written to the data directory (or to the directory configured with --binlog-directory). The files are named binlog-000000.ibb, binlog-000001.ibb, ... and so on.
The size of each binlog file is determined by the value of max_binlog_size (by default 1 GB). The binlog files are pre-allocated, so they will always have the configured size, with the last one or two files being possibly partially empty. The exception is when the command FLUSH BINARY LOGS is used; then the last active binlog file will be truncated to the used part of it, and binlog writes will continue in the following file.
The list of current binlog files can be obtained with the command SHOW BINLOG EVENTS. Note that there is no binlog index file (.index) like with the traditional binlog format, nor are there any GTID index files (.idx) or GTID state (.state) file (.state).
Binlog files can be purged (removed) automatically after a configured time or disk space usage, provided they are no longer needed by active replication slaves or for possible crash recovery. This is configured using the options binlog_expire_log_seconds, binlog_expire_log_days, max_binlog_total_size, and slave_connections_needed_for_purge.
The contents of binlog files can be inspected in two ways:
- From within the server, using the command SHOW BINLOG EVENTS.
- Independent of the server, using the mariadb-binlog command-line program.
Unlike in the traditional binlog format, one binlog event can be stored in multiple different binlog files, and different parts of individual events can be interleaved with one another in each file. The mariadb-binlog program will coalesce the different parts of each event as necessary, so the output of the program is a consistent, non-interleaved stream of events. To obtain a correct seequnce of events across multiple binlog files, all binlog files should be passed to the mariadb-binlog program at once in correct order; this ensures that events that cross file boundaries are included in the output exactly once.
When using the -start-position and -stop-position options of mariadb-binlog, it is recommended to use GTID positions. The event file offsets used in the tranditional binlog format are not used in the new binlog, and will mostly be reported as zero.
Using the new binlog with 3rd-party programs
The new binlog uses a different on-disk format than the traditional binlog. The format of individual replication events is the same; however the files stored on disk are page-based, and each page has some encapsulation of event data to support splitting events in multiple pieces etc.
This means that existing 3rd-party programs that read the binlog files directly will need to be modified to support the new format. Until then, such programs will require using the traditional binlog format.
The protocol for reading binlog data from a running server (eg. for a connecting slave) is however mostly unchanged. This means existing programs that read binlog events from a running server may be able to function unmodified with the new binlog. Similarly, mariadb-binlog with the --read-from-remote-server option works as usual.
A difference is that file offsets and file bondaries are no longer meaningful and no longer reported to the connecting client. There are no rotate events at the end of a file to specify the name of the following file, nor is there a new format description event at the start of each new file. Effectively, the binlog appears as a single unbroken stream of events to clients. The position from which to start receiving binlog events from the server should be specified using a GTID position; specifying a filename and file offset is not available.
Documentation of the binlog file format
TBD.
Not supported
A few things are not supported with the new binlog implementation. Some of these should be supported in a later version of MariaDB.
- Old-style filename/offset replication positions are not available with the new binlog. Slaves to be configured to use GTID (this is the default). Event offsets are generally reported as zero. MASTER_POS_WAIT() is not available, MASTER_GTID_WAIT() should be used instead. Similarly, BINLOG_GTID_POS() is not available.
- Semi-synchronous replication is not supported in the first version. It will be supported as normal eventually using the AFTER_COMMIT option. The AFTER_SYNC option cannot be supported, as the expensive two-phase commit between binlog and engine is no longer needed (AFTER_SYNC waits for slave acknowledgement in the middle of the two-phase commit).
- In the initial version, only InnoDB is available as an engine for the binlog (--binlog-storage-engine=innodb). It the future, other transactional storage engines could implement storing the binlog themselves (performance is best when the binlog is implemented in the same engine as the tables that are updated).
- The sync_binlog option is no longer needed and is effectively ignored. Since the binlog files are now crash-safe without needing any syncing. The durability of commits is now controlled solely by the --innodb-flush-log-at-trx-commit option, which now applies to both binlog files and InnoDB table data.
- The command RESET MASTER TO is not available with the new binlog.
- Binlog encryption is not available. It is suggested to use filesystem-level encryption facilities of the operating system instead.
Architectural considerations.
The fundamental problem with the binlog is that it functions as a
transactional log, but it is separate from the InnoDB transactional log.
This is very unoptimal. To ensure consistency in case of crash, a two-phase
commit protocol is needed that requires two fsync per commit, which is very
costly in terms of performance. And it causes a lot of complexity in the
code as well. We should make it so that there is only a single transactional
log ("single source of truth") used, at least for the case where only a
single storage engine is used (eg. InnoDB) for all tables.
Some different options for doing this can be considered (explained in detail
below):
- Implement a new binlog format that is stored in a new InnoDB tablespace
type (or more generally in any storage engine that implements the
appropriate new API for binlog). - Keep the current binlog format, extend the InnoDB redo log format with
write-ahead records for binlog writes. Integrate binlog writes with InnoDB
checkpointing and buffer pool flush. - Store the binlog events directly inside the InnoDB redo log. Implement
log archiving of the InnoDB log to preserve old binlog data as long as
desired. - (Mentioned only for completeness): Implement a general redo log facility
on the server level, and change both InnoDB and binlog to use that facility.
I am currently working on option (1), inspired by talks I had with Marko
Mäkelä at the MariaDB fest last Autumn. He suggested that a new type of
tablespace be added to InnoDB which would hold the binlog, and explained
that this would require relative small changes in the InnoDB code.
I think this is the best option. The InnoDB log and tablespace
implementation is very mature, it is very good to be able to re-use it for
the binlog. The integration into InnoDB looks to be very clean, and all the
existing infrastructure for log write, recovery, checkpointing, buffer pool
can be re-used directly. All the low-level detail of how the binlog is
stored on disk can be handled efficiently inside the InnoDB code.
Like option (2), the binlog remains available as a simple set of files,
which is much the same as with the legacy binlog. We just write them
differently, using the InnoDB redo log/tablespace mechanism to get better
crash recovery. Though unlike option (2), with option (1) the file format
will be somewhat different.
This option will require a lot of changes in the binlog and replication
code, which is the main cost of choosing this option. I have a lot of
experience with the MariaDB replication code, and I think this is feasible.
And I think there are another set of huge benefits possible from
implementing a new binlog format. The existing binlog format is very naive
and neither very flexible, nor well suited as a high-performance
transactional log. So changing the binlog format is something that should be
done eventually anyway.
Option (2) would also be feasible I think, and has the advantage of needing
less changes to the replication code. Monty mentioned seeing a patch that
sounded something like this. The main disadvantage is that I think this will
require complex interaction between low-level InnoDB checkpointing code and
low-level binlog writing code, which I fear will eventually lead to complex
code that will be hard to maintain and will stiffle further innovation on
either side. It also doesn't address the other problems with the current
binlog format. To me, letting the storage engine control how it stores data
transactionally - including the binlog events - is the "right" solution, and
worth persuing over a quicker hack that tries to avoid changing code.
Option (3) is also interesting. The idea would be that the binlog becomes
identical to the InnoDB redo log, storing the binlog data interleaved with
the InnoDB log records. This is conceptually simpler than options (1) and
(2), in the sense that we don't have to first write-ahead-log a record for
modifying binlog data, and then later write the actual data modification to
a separate tablespace/file.
But the InnoDB log is cyclic, and old data is overwritten as the log LSN
wraps over the end. Thus, this option (3) will require implementing log
archiving in InnoDB, which I am not sure how much work will be required.
Either the binlog data could be archived by copying out asynchroneously to
persistent binlog files, which becomes somewhat similar to option (1) or (2)
then perhaps. Or InnoDB could be changed to create a new log file at
wrap-over, renaming the old one to archive it, though this will leave the
binlog data somewhat "dilluted", mixed up with InnoDB internal redo records.
One pragmatic reason I've chosen option (1) over this option (3) for now is
that I am more comfortable with doing large changes to replication code than
to InnoDB code. Also, option (3) would more drastically change the way users
can work with the binlog files, as a large amount of the most recent data
would be sitting inside the InnoDB redo log and not in dedicated binlog
files, unlike options (1) and (2). Still, option (3) is an interesting idea
and has the potential to reduce the write amplification that will occur from
(1) and (2). So I'm eager to hear any suggestions around this.
Option (4) I mention only for completeness. Somehow, the "clean" way to
handle transactional logging would be if the server layer provides a general
logging service, and all the components would then use this for logging.
InnoDB and the binlog, but also all the other logs or log-like things we
have, eg. Aria, DDL log, partitioning, etc.
However, I don't think it makes sense to try to discard the whole InnoDB
write-ahead logging code and replace it with some new implementation done on
the server level. And I'm not even sure it makes sense from a theoretical
point of view - somehow, the logging method used is intrinsically a property
of the storage engine; it seems dubious if a general server-level log
facility could be designed that would be optimal for both InnoDB and
RocksDB, for example.
High-level design.
Introduce a new option --binlog-storage-engine=innodb. Extend the storage
engine API with the option for an engine to provide a binlog implementation,
supported by InnoDB initially. Initially the option cannot be changed
dynamically.
When --binlog-storage-engine=innodb, the binlog files will use a different
format, stored as a new type of InnoDB tablespace. It should support that
the old part of the binlog is the legacy format and the new is the InnoDB
format, to facilitate migrations. Maybe also support going back again,
though this is less critical initially.
Conceptually, the binlog will look much the same, consisting of a number of
files binlog-000000.ibb, binlog-000001.ibb, ... The main difference is that
the files are written using InnoDB tablespace code instead of direct OS
open() and write(), in order to provide atomicity of writes and crash
recovery. Basically changing MYSQL_BIN_LOG::write_cache() and
MYSQL_BIN_LOG::write() to call into InnoDB for the actual data write. And
then a number of other miscellaneous modifications as necessary and to
accomodate a somewhat different file format.
A goal is to clean up some of the unnecessary complexity of the legacy
binlog format. The old format will be supported for the foreseeable future,
so the new format can break backwards compatibility. For example, the name
of binlog files will be fixed, binlog-<NNNNNN>.ibb, so each file can be
identified solely by its number NNNNNN. The option to decide the directory
in which to store the binlog files should be supported though.
I think we can require the slaves to use GTID when
--binlog-storage-engine=innodb is enabled on the master. This way we can
avoid exposing slaves to internal implementation details of the binlog, and
the slaves no longer need to update the file relay-log.info at every commit.
We should also be able to get rid of the Format_description_log_event and
the Rotate_log_event at the start of every binlog file, so that the slave
can view the events from the master as one linear stream and not care about
how the data is split into separate binlog files on the master.
The binlog format will be page based. This will allow pre-allocating the
binlog files and efficiently writing them page by page. And it will be
possible to access the files without scanning them sequentially from the
start; eg. we can find the last event by reading the last page of the file,
binary-searching for the last used page if the binlog file is partially
written.
The GTID indexes can be stored inside the same tablespace as the binlog data
(eg. at the end of the tablespace), avoiding the need for a separate index
file. GTID index design is still mostly TBD, but I think it can be
implemented so that indexes are updated transactionally as part of the
InnoDB commit and no separate crash recovery of GTID indexes is needed.
With GTID indexes being guaranteed available, we can use them to obtain the
GTID state at the start of each binlog file, and avoid the need for the
Gtid_list_log_event at the start of the binlog.
With a page-based log with extensible format, metadata can be added to the
binlog that is only used on the master without having to introduce new
replication events that are not relevant to the replication on the slave.
This can be used eg. to eliminate the Binlog_checkpoint_log_event, for
example. Possibly the binlog checkpoint mechanism can be completely avoided
for the --binlog-storage-engine=innodb case, since there is no more 2-phase
commit needed in the common case of an InnoDB-only transaction.
The existing binlog checksum and encryption will no longer be used, instead
the standard InnoDB checksums and encryption will be reused.
The new implementation will recover the binlog and the InnoDB tables into a
consistent state after a crash even with --innodb-flush-log-at-trx-commit=0.
But if slaves are connected, a complication is that a slave could have
received a transaction just before a master crash that is no longer present
on the master after crash recovery, if transactions are sent to slave before
they become durable on the master. One way to handle thisis to have the
binlog background thread asynchroneously request a log sync from InnoDB
after commit, and delay the sending of binlog events to the slave until
after the corresponding InnoDB LSN has become durable.
Implementation plan.
The storage engine API must be extended to provide a facilities for writing
to the binlog and for reading from the binlog. The design of the API is TBD,
should be discussed to try to make it generic and suitable for other engines
than InnoDB.
When writing to binlog in InnoDB, the central idea is to use the same
mini-transaction (mtr) that marks the transaction as committed in InnoDB.
This is what makes the binlog data guaranteed consistent with the InnoDB
table data without the need for two-phase commit.
The initial version I think can use the existing binlog group commit
framework; this will simplify the implementation. This will thus keep the
LOCK_commit_ordered and the queue_for_group_commit() mechanisms. Later work
can then be to see if this can be even further improved in terms of
scalability.
For multi-engine transactions, I have not worked out the details yet. But I
think this will work much the same as for the legacy binlog. Two-phase
commit will still be used/needed (though if one engine is InnoDB, there will
be one less fsync() needed of course).
I want to implement that large event groups can be split into multiple
chunks in the binlog that no longer need to be consecutive. The final chunk
will be the one that contains the GTID and marks the event group binlogged;
this final chunk will then refer back to the other parts. This way, a large
transactions can be binlogged without stalling the writing of other
(smaller) transactions in parallel, which is a bottleneck in the legacy
binlog. And it avoids problems with exceeding the maximum size of an mtr.
In the first version, I think the binlog reader in the dump thread will
collect and concatenate the different chunks before sending them to the
slave, so simplify the initial implementation. But a later change could
allow the slave to receive the different chunks interleaved between
different event groups. This can even eventually allow the slave to
speculatively execute events even before the transaction has committed on
the master, to potentially reduce slave lag to less than the time of even a
single transaction; this would be a generalisation of the
--binlog-alter-two-phase feature.
The binlog will be stored in separate tablespace files, each of size
--max-binlog-size. The binlog files will be pre-allocated by a background
thread. Since event groups can spill over to the next file, each file can be
a fixed size, and hopefully also the rotate events will no longer be
necessary. Purging should work much the same as before, though the engine
will need some way to communicate to the server about binlog files are there.
A busy server will quickly cycle through tablespace files, and we want to
avoid "using up" a new tablespace ID for each file (InnoDB tablespace IDs
are limited to 2**32 and are not reused). Two system tablespace IDs will be
reserved for the binlog, and new binlog files will alternate between them.
This way, the currently written binlog can be active while the previous one
is being flushed to disk and the remaining writes checkpointed. Once the
previous log has been flushed completely, its tablespace ID can be re-used
for the next, pre-allocated binlog file and be ready for becoming active.
This way, the switching to the next binlog file should be able to occur
seamlessly, without any stalls, as long as page flushing can keep up. The
flushing of binlog pages will be prioritised, to avoid stalling binlog
writes, to free up buffer pool pages that can be used more efficiently than
holding binlog data, and to quickly make the binlog files readable from
outside the server (eg. with mysqlbinlog).
The binlog dump thread that reads from the binlog and sends the data to
slaves will use a binlog reading API implemented in InnoDB. I will prefer to
read directly from the binlog files, in order to reduce pressure on the
InnoDB buffer pool etc. A slave that connects from an old position back in
time may need to read a lot of old data from the binlogs; there is little
value in loading this data into the buffer pool, evicting other more useful
pages. The reader can lookup in the InnoDB buffer pool with the
BUF_GET_IF_IN_POOL flag. This way, the data can be accessed from the buffer
pool if it is present. If not present, we can be sure that the data will be
in the data file, and can read it from the file directly. If the data is
known to be already flushed to disk before the specific binlog position,
then the buffer pool lookup can be skipped altogether.
The mysqlbinlog program will need to be extended somehow to be able to read
from an InnoDB tablespace (or in general other storage engine). I think this
means mysqlbinlog needs some kind of engine plugin facility for reading
binlog. Note that the -read-from-remote-server option will also be available
to read data from a mysqlbinlog that doesn't the new format, or to read the
very newest data before it gets written to disk.
Final words.
This is still an early draft of the feature, as it is being worked on and
refined; things are subject to change. And this also means that things are
open to change, according to any suggestions with a good rationale.
Links to additional design discussions:
File format: https://lists.mariadb.org/hyperkitty/list/developers@lists.mariadb.org/thread/ZS45NCMOYJRHPHLNZYDQLYXXQGTDL3P3/
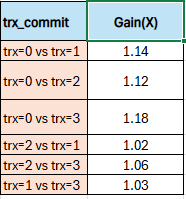
Benchmarking: https://lists.mariadb.org/hyperkitty/list/developers@lists.mariadb.org/thread/XMDEHA253XKYIFFKBMV7Q3QQ2ILKHMP5/
Low-level design points: https://lists.mariadb.org/hyperkitty/list/developers@lists.mariadb.org/thread/OS4NJ5QLIW6YV6THYUOJNFXJPSWWVE77/
Attachments
Issue Links
- blocks
-
-
- Open
-
-
-
- Closed
-
- causes
-
MDEV-38225 mariabackup stores all binary logs when server runs with binlog-storage-engine
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-

- Stalled
-
-
-
- Closed
-
- includes
-
-
- Open
-
-
MDEV-37487 Create Binlog-in-Innodb mariadb-binlog MTR tests
-
- Closed
-
- relates to
-
-
- Open
-
-
MDEV-38304 Innodb Binlog to be Stored in Archived Redo Log
-
- Open
-
-
-
- Open
-
-
-
- Open
-
-
-
- Open
-
-
-
- Stalled
-
-
-
- Stalled
-
-
-
- Open
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Open
-
-
-
- Closed
-
-
-
- Open
-
- split to
-
-
- Stalled
-
-
-
- Open
-
-
-
- In Testing
-
-
-
- Open
-
- links to
