Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Fixed
-
10.11, 11.4, 11.6(EOL)
-
None
Description
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try.
TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive.
I tried on Windows, and it is just slow, and this case is below
I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when
I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer.
If tmpdir points to persistent disk, effects are about the same on Linux as they are on Windows
Below, my test case:
Step 0 - server parameters
We run load "in-memory", and both bufferpool and redo log will be larger than the IBD file.
[mysqld]
|
innodb_log_file_size=20G
|
innodb_buffer_pool_size=20G
|
innodb-buffer-pool-load-at-startup=OFF
|
innodb_buffer_pool_dump_at_shutdown=OFF
|
innodb_stats_auto_recalc=0
|
Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file)
sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare
|
Elapsed time (seconds): 273.673
Process IO Read Bytes : 14387837038
Process IO Write Bytes : 19291281550
Step 2: backup sbtest.sbtest1 table
mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" |
Elapsed time (seconds): 36.482
restart server
Step 3: Load this data again, without bulk optimization
mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" |
Elapsed time (seconds): 240.996
Process Read Bytes 9916879781
Process Write Bytes 15149246158
Restart server again,
Step 4: Load the same data once more, with bulk optimization (enforced by setting unique_checks=0,foreign_key_checks=0)
mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" |
This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory.
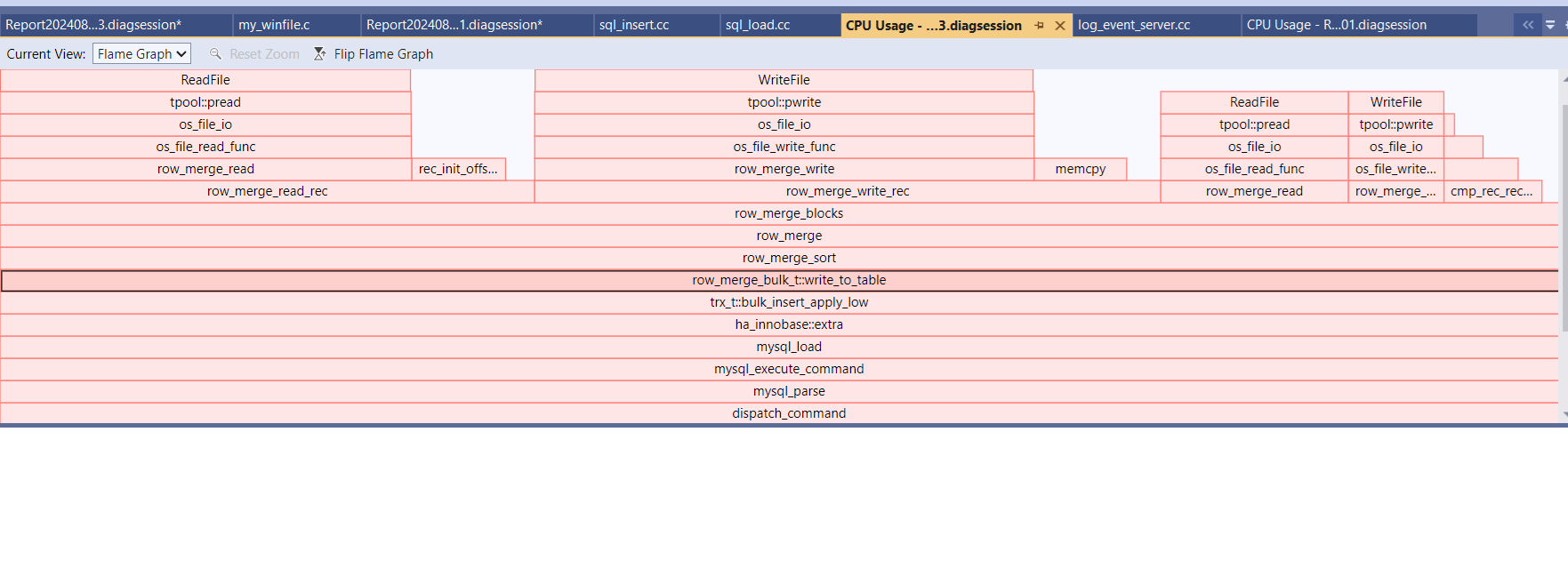
When it is slow, CPU is at about 3%, busy with some reads and writes 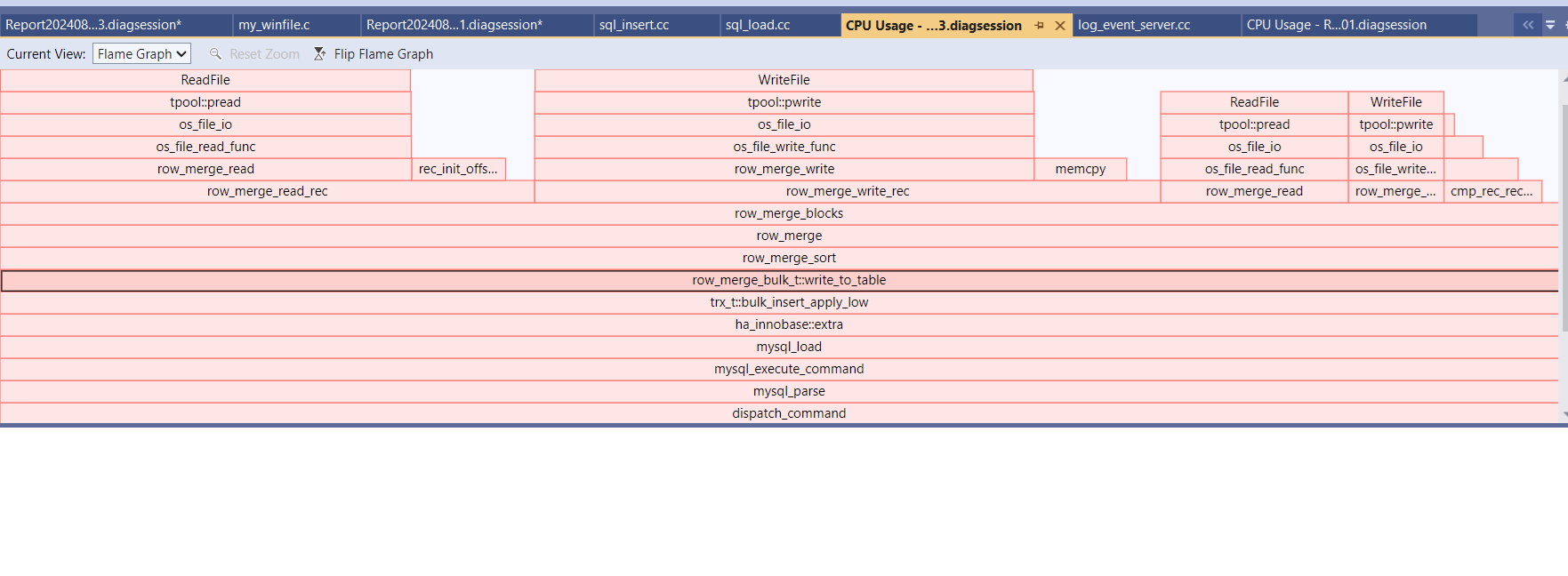 to temp. files.
to temp. files.
Elapsed time (seconds): 371.664
Process Read Bytes: 167433868189
Process Write Bytes: 170475124430
Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) , and sysbench "prepare"
| Execution Time | IO-read Gbytes | IO-write Gbytes | |
|---|---|---|---|
| Sysbench prepare | 273 | 13.4 | 17.97 |
| LOAD DATA NO-Bulk | 240 | 9.24 | 14.11 |
| LOAD DATA Bulk | 371 | 155.93 | 158.77 |
Attachments
Issue Links
- duplicates
-
-
- Closed
-
- relates to
-
MDEV-24621 In bulk insert, pre-sort and build indexes one page at a time
-
- Closed
-
-
-
- Closed
-
-
MDEV-34832 Support adding AUTO_INCREMENT flag to existing numeric using INPLACE
-

- Open
-
-
MDEV-33188 Enhance mariadb-dump and mariadb-import capabilities similar to MyDumper
-
- Stalled
-
Activity
| Field | Original Value | New Value |
|---|---|---|
| Summary | Draft: Innodb bulk load is bugs, as tested with LOAD DATA INFILE | Draft: Innodb bulk load high IO, crashes, OOM, as tested with LOAD DATA INFILE |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Test case: Step 1. Using sysbench, load a single table with 50M rows {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Wait until purge becomes quiet, restart server Step 3: Load this data again, without bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Step 4: Restart server again, *with* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} compare execution times from Step 3 and Step 4 |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Test case: Step 0: use following config file with the server {code:ini} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_stats_auto_recalc=0 {code} start server with --innodb-buffer-pool-size=20G --innodb-log-file-size=20G - because the table we'll be using will be large-ish Step 1. Using sysbench, load a single table with 50M rows. {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Wait until purge becomes quiet, restart server Step 3: Load this data again, without bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Step 4: Restart server again, *with* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} compare execution times from Step 3 and Step 4 |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Test case: Step 0: use following config file with the server {code:ini} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_stats_auto_recalc=0 {code} start server with --innodb-buffer-pool-size=20G --innodb-log-file-size=20G - because the table we'll be using will be large-ish Step 1. Using sysbench, load a single table with 50M rows. {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Wait until purge becomes quiet, restart server Step 3: Load this data again, without bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Step 4: Restart server again, *with* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} compare execution times from Step 3 and Step 4 |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Test case: I use Windows and C:/path/to/file in the following description, adjust to your OS if required. Step 0: use following config file to start the server {code:ini} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_fast_shutdown=0 innodb_stats_auto_recalc=0 # unimportant {code} Step 1. Using sysbench, load a single table with 50M rows. {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Restart server Step 3: Load this data again, *without* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. Step 4: Restart server again, *with* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. compare execution times, and IO read/write bytes from Step 3 and Step 4. Results: |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Test case: I use Windows and C:/path/to/file in the following description, adjust to your OS if required. Step 0: use following config file to start the server {code:ini} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_fast_shutdown=0 innodb_stats_auto_recalc=0 # unimportant {code} Step 1. Using sysbench, load a single table with 50M rows. {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Restart server Step 3: Load this data again, *without* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. Step 4: Restart server again, *with* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. compare execution times, and IO read/write bytes from Step 3 and Step 4. Results: |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR : bulk optimization is slow (a lot of temp IO), the temp files for merging are huge. It is definitely slower as "no bulk optimization". I tried to give optimization benefit of doubt, and use memory backed /tmp, Got crashes when temp is full. When I set tmpfs size as large as memory, got server process killed (suspect it is OOM-killer) Test case: I use Windows and C:/path/to/file in the following description, adjust to your OS if required. Step 0: use following config file to start the server {code:ini} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_fast_shutdown=0 innodb_stats_auto_recalc=0 # unimportant {code} Step 1. Using sysbench, load a single table with 50M rows. {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Restart server Step 3: Load this data again, *without* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. Step 4: Restart server again, *with* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. compare execution times, and IO read/write bytes from Step 3 and Step 4. Results: |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR : bulk optimization is slow (a lot of temp IO), the temp files for merging are huge. It is definitely slower as "no bulk optimization". I tried to give optimization benefit of doubt, and use memory backed /tmp, Got crashes when temp is full. When I set tmpfs size as large as memory, got server process killed (suspect it is OOM-killer) Test case: I use Windows and C:/path/to/file in the following description, adjust to your OS if required. Step 0: use following config file to start the server {code:ini} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_fast_shutdown=0 innodb_stats_auto_recalc=0 # unimportant {code} Step 1. Using sysbench, load a single table with 50M rows. {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Restart server Step 3: Load this data again, *without* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. Step 4: Restart server again, *with* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. compare execution times, and IO read/write bytes from Step 3 and Step 4. Results: |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR : bulk optimization is slow (a lot of temp IO), the temp files for merging are huge. It is definitely slower as "no bulk optimization". I tried to give optimization benefit of doubt, and use memory backed /tmp, Got crashes when temp is full. When I set tmpfs size as large as memory, got server process killed (suspect it is OOM-killer) *Test case (Windows)* I use Windows and C:/path/to/file in the following description, adjust to your OS if required. Step 0: use following config file to start the server {code:ini} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_fast_shutdown=0 innodb_stats_auto_recalc=0 # unimportant {code} Step 1. Using sysbench, load a single table with 50M rows. {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Restart server Step 3: Load this data again, *without* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. Step 4: Restart server again, *with* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. compare execution times, and IO read/write bytes from Step 3 and Step 4. Results: |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR : bulk optimization is slow (a lot of temp IO), the temp files for merging are huge. It is definitely slower as "no bulk optimization". I tried to give optimization benefit of doubt, and use memory backed /tmp, Got crashes when temp is full. When I set tmpfs size as large as memory, got server process killed (suspect it is OOM-killer) *Test case (Windows)* I use Windows and C:/path/to/file in the following description, adjust to your OS if required. Step 0: use following config file to start the server {code:ini} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_fast_shutdown=0 innodb_stats_auto_recalc=0 # unimportant {code} Step 1. Using sysbench, load a single table with 50M rows. {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Restart server Step 3: Load this data again, *without* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. Step 4: Restart server again, *with* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. compare execution times, and IO read/write bytes from Step 3 and Step 4. Results: |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR : bulk optimization is slow (a lot of temp IO), the temp files for merging are huge. It is definitely slower as "no bulk optimization". I tried to give optimization benefit of doubt, and use memory backed /tmp, Got crashes when temp is full. When I set tmpfs size as large as memory, got server process killed (suspect it is OOM-killer) *Test case (Windows)* I use Windows and C:/work/sbtest1.data to store the dump, in the following description, adjust path for your OS if required. Step 0: use following config file to start the server {code:ini} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_fast_shutdown=0 innodb_stats_auto_recalc=0 # unimportant {code} Step 1. Using sysbench, load a single table with 50M rows. {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Restart server Step 3: Load this data again, *without* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. Step 4: Restart server again, *with* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. compare execution times, and IO read/write bytes from Step 3 and Step 4. Results: |
| Attachment | bulk_flame.png [ 73912 ] |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR : bulk optimization is slow (a lot of temp IO), the temp files for merging are huge. It is definitely slower as "no bulk optimization". I tried to give optimization benefit of doubt, and use memory backed /tmp, Got crashes when temp is full. When I set tmpfs size as large as memory, got server process killed (suspect it is OOM-killer) *Test case (Windows)* I use Windows and C:/work/sbtest1.data to store the dump, in the following description, adjust path for your OS if required. Step 0: use following config file to start the server {code:ini} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_fast_shutdown=0 innodb_stats_auto_recalc=0 # unimportant {code} Step 1. Using sysbench, load a single table with 50M rows. {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Restart server Step 3: Load this data again, *without* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. Step 4: Restart server again, *with* bulk optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} On Windows, you can see IO read bytes and IO write bytes by the server process. compare execution times, and IO read/write bytes from Step 3 and Step 4. Results: |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Test case: h2. Step 1. Using sysbench, load a single table with 50M rows {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again,* without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
| Link |
This issue relates to |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Test case: h2. Step 1. Using sysbench, load a single table with 50M rows {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again,* without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again,* without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again,* without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
| Summary | Draft: Innodb bulk load high IO, crashes, OOM, as tested with LOAD DATA INFILE | Draft: Innodb bulk load : high IO, crashes on Linux, OOM on Linux, as tested with LOAD DATA INFILE |
| Summary | Draft: Innodb bulk load : high IO, crashes on Linux, OOM on Linux, as tested with LOAD DATA INFILE | Innodb bulk load : high IO, crashes on Linux, OOM on Linux, as tested with LOAD DATA INFILE |
| Assignee | Marko Mäkelä [ marko ] |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
| Component/s | Storage Engine - InnoDB [ 10129 ] |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, corresponding to [this flamegraph | ^ !bulk_flame.png|thumbnail! Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, corresponding to [this flamegraph | ^ !bulk_flame.png|thumbnail! Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization (enforced by setting unique_checks=0,foreign_key_checks=0) {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization (enforced by setting unique_checks=0,foreign_key_checks=0) {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization (enforced by setting unique_checks=0,foreign_key_checks=0) {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) , and sysbench "prepare" || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization (enforced by setting unique_checks=0,foreign_key_checks=0) {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) , and sysbench "prepare" || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 0 - server parameters We run load "in-memory", and both bufferpool and redo log will be larger than the IBD file. {noformat} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_stats_auto_recalc=0 {noformat} h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization (enforced by setting unique_checks=0,foreign_key_checks=0) {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) , and sysbench "prepare" || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. Below, my test case: h2. Step 0 - server parameters We run load "in-memory", and both bufferpool and redo log will be larger than the IBD file. {noformat} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_stats_auto_recalc=0 {noformat} h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization (enforced by setting unique_checks=0,foreign_key_checks=0) {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) , and sysbench "prepare" || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. If tmpdir points to persistent disk, effects are about the same on Linux as they are on Windows Below, my test case: h2. Step 0 - server parameters We run load "in-memory", and both bufferpool and redo log will be larger than the IBD file. {noformat} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_stats_auto_recalc=0 {noformat} h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization (enforced by setting unique_checks=0,foreign_key_checks=0) {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) , and sysbench "prepare" || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. If tmpdir points to persistent disk, effects are about the same on Linux as they are on Windows Below, my test case: h2. Step 0 - server parameters We run load "in-memory", and both bufferpool and redo log will be larger than the IBD file. {noformat} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_stats_auto_recalc=0 {noformat} h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 h2. Step 4: Restart server again, *with bulk* optimization (enforced by setting unique_checks=0,foreign_key_checks=0) {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) , and sysbench "prepare" || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. If tmpdir points to persistent disk, effects are about the same on Linux as they are on Windows Below, my test case: h2. Step 0 - server parameters We run load "in-memory", and both bufferpool and redo log will be larger than the IBD file. {noformat} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_stats_auto_recalc=0 {noformat} h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 Restart server again, h2. Step 4: Load *with bulk* optimization (enforced by setting unique_checks=0,foreign_key_checks=0) {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) , and sysbench "prepare" || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. If tmpdir points to persistent disk, effects are about the same on Linux as they are on Windows Below, my test case: h2. Step 0 - server parameters We run load "in-memory", and both bufferpool and redo log will be larger than the IBD file. {noformat} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_stats_auto_recalc=0 {noformat} h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 Restart server again, h2. Step 4: Load *with bulk* optimization (enforced by setting unique_checks=0,foreign_key_checks=0) {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) , and sysbench "prepare" || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. If tmpdir points to persistent disk, effects are about the same on Linux as they are on Windows Below, my test case: h2. Step 0 - server parameters We run load "in-memory", and both bufferpool and redo log will be larger than the IBD file. {noformat} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_stats_auto_recalc=0 {noformat} h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 Restart server again, h2. Step 4: Load the same data once more, *with bulk* optimization (enforced by setting unique_checks=0,foreign_key_checks=0) {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) , and sysbench "prepare" || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
As noted in MDEV-34832, another bottleneck are AUTO_INCREMENT columns.
| Link | This issue relates to MDEV-34832 [ MDEV-34832 ] |
| Link |
This issue relates to |
| Link |
This issue relates to |
| Link | This issue relates to MDEV-33188 [ MDEV-33188 ] |
| Fix Version/s | 11.6 [ 29515 ] |
Would providing a mechanism to enable only MDEV-515 but not MDEV-24621 for LOAD statements address both this and MDEV-34719?
| Link |
This issue relates to |
marko , I think it would, for my use case.
I'm still wondering how bulk is supposed with mysqldump style inserts. Is MDEV-24621 sufficiently well tested, on tens of GB inputs files?
Unfortunately, to my knowledge there is no user interface for claiming that the data is already sorted. If we had that, we could skip the merge sorting step and proceed straight to building the clustered index B-tree page by page. An optimization to skip sorting for the PRIMARY KEY is only implemented for ha_innobase::inplace_alter_table() when it is rebuilding the table in such a way that the ordering of records is not changing. This even allows some redefinition of the PRIMARY KEY, such as removing the last columns of a multi-column PRIMARY KEY.
Ok, so , in practice, this MDEV-24621 would turn to pessimization, and an attempt to force it switching autocommit off in mysqldump will turn out in a disaster in any sizable dump, right?
| Affects Version/s | 10.11 [ 27614 ] | |
| Affects Version/s | 11.4 [ 29301 ] |
| Fix Version/s | 10.11 [ 27614 ] | |
| Fix Version/s | 11.2 [ 28603 ] | |
| Fix Version/s | 11.4 [ 29301 ] |
| Fix Version/s | 11.6(EOL) [ 29515 ] |
| Fix Version/s | 11.2(EOL) [ 28603 ] |
| Assignee | Marko Mäkelä [ marko ] | Thirunarayanan Balathandayuthapani [ thiru ] |
I think that to improve this, we should do the following:
- Disable the sorting for the PRIMARY KEY within LOAD DATA, similar to what we do in some forms of ALTER TABLE (innobase_pk_order_preserved()).
- Ensure that the debug assertion in PageBulk::insertPage() for misordered records will not be tripped.
- That is, make the bulk insert tolerate unsorted data in some way.
- Maybe, if unsorted data is encountered, finish the bulk insert part and continue by inserting records one by one.
- There must not be any extra record comparisons for any other operation than {{LOAD DATA}, and not for any secondary index.
| Status | Open [ 1 ] | In Progress [ 3 ] |
| Assignee | Thirunarayanan Balathandayuthapani [ thiru ] | Marko Mäkelä [ marko ] |
| Status | In Progress [ 3 ] | In Review [ 10002 ] |
| Description |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. If tmpdir points to persistent disk, effects are about the same on Linux as they are on Windows Below, my test case: h2. Step 0 - server parameters We run load "in-memory", and both bufferpool and redo log will be larger than the IBD file. {noformat} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_stats_auto_recalc=0 {noformat} h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 Restart server again, h2. Step 4: Load the same data once more, *with bulk* optimization (enforced by setting unique_checks=0,foreign_key_checks=0) {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0, load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) , and sysbench "prepare" || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
Found by accident, trying to understand why sysbench loads its data faster than
mariadb-import --parallel. Mostly likely present before 11.6, did not try. TLDR: for me, Bulk load turns out to be 1.5 times slower (on fast NVME), and more than 15 times more IO intensive. I tried on Windows, and it is just slow, and this case is below I tried on Linux, hoping that maybe BULK relies on temp directory being in memory, but got crash (tmpdir exhausted), or when I allowed tmpfs to be 32GB (whole memory), then server process got killed, probably Linux peculiarity the OOM killer. If tmpdir points to persistent disk, effects are about the same on Linux as they are on Windows Below, my test case: h2. Step 0 - server parameters We run load "in-memory", and both bufferpool and redo log will be larger than the IBD file. {noformat} [mysqld] innodb_log_file_size=20G innodb_buffer_pool_size=20G innodb-buffer-pool-load-at-startup=OFF innodb_buffer_pool_dump_at_shutdown=OFF innodb_stats_auto_recalc=0 {noformat} h2. Step 1. Using sysbench, load a single table with 50M rows (~11GB ibd file) {code:bash} sysbench oltp_read_write --mysql-user=root --tables=1 --table-size=50000000 --threads=1 prepare {code} Elapsed time (seconds): 273.673 Process IO Read Bytes : 14387837038 Process IO Write Bytes : 19291281550 h2. Step 2: backup sbtest.sbtest1 table {code:bash} mariadb -uroot -e "select * into outfile 'C:/work/sbtest1.data' from sbtest.sbtest1" {code} Elapsed time (seconds): 36.482 restart server h2. Step 3: Load this data again, *without bulk* optimization {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} Elapsed time (seconds): 240.996 Process Read Bytes 9916879781 Process Write Bytes 15149246158 Restart server again, h2. Step 4: Load the same data once more, *with bulk* optimization (enforced by setting unique_checks=0,foreign_key_checks=0) {code:bash} mariadb -uroot -e "truncate sbtest.sbtest1; set unique_checks=0,foreign_key_checks=0; load data infile 'C:/work/sbtest1.data' into table sbtest.sbtest1" {code} This is the step that is very slow, pegs the disk at ~1GB reads and writes, and this is where it crashes on Linux, if /tmp is memory. When it is slow, CPU is at about 3%, busy with some reads and writes !bulk_flame.png|thumbnail! to temp. files. Elapsed time (seconds): 371.664 Process Read Bytes: 167433868189 Process Write Bytes: 170475124430 h2. Compare execution times and IO usage from Step 3 (without bulk) and Step 4(with bulk) , and sysbench "prepare" || || Execution Time || IO-read Gbytes|| IO-write Gbytes || |Sysbench prepare | 273| 13.4| 17.97| | LOAD DATA NO-Bulk | 240 | 9.24| 14.11| | LOAD DATA Bulk | 371 | 155.93| 158.77| |
| Assignee | Marko Mäkelä [ marko ] | Thirunarayanan Balathandayuthapani [ thiru ] |
| Status | In Review [ 10002 ] | Stalled [ 10000 ] |
| Fix Version/s | 10.11.11 [ 29954 ] | |
| Fix Version/s | 10.11 [ 27614 ] | |
| Fix Version/s | 11.4 [ 29301 ] | |
| Resolution | Fixed [ 1 ] | |
| Status | Stalled [ 10000 ] | Closed [ 6 ] |
| Fix Version/s | 11.4.5 [ 29956 ] | |
| Fix Version/s | 11.7.2 [ 29914 ] |
| Link |
This issue duplicates |
Did you try to specify a larger innodb_sort_buffer_size to prevent the use of temporary files for merge sorting?
If the data is typically sorted by PRIMARY KEY, I think that we would benefit from a parameter or statement attribute that specifies this, so that the bulk load could avoid sorting the data, and simply throw an error when unsorted data is encountered. Any secondary indexes would still have to use a sort buffer. For ALTER TABLE and OPTIMIZE TABLE there is some logic in innobase_pk_order_preserved() to skip the unnecessary sorting.