Details
-
Bug
-
Status: Open (View Workflow)
-
 Major
Major
-
Resolution: Unresolved
-
10.4.24
-
None
-
CentOS 7
Description
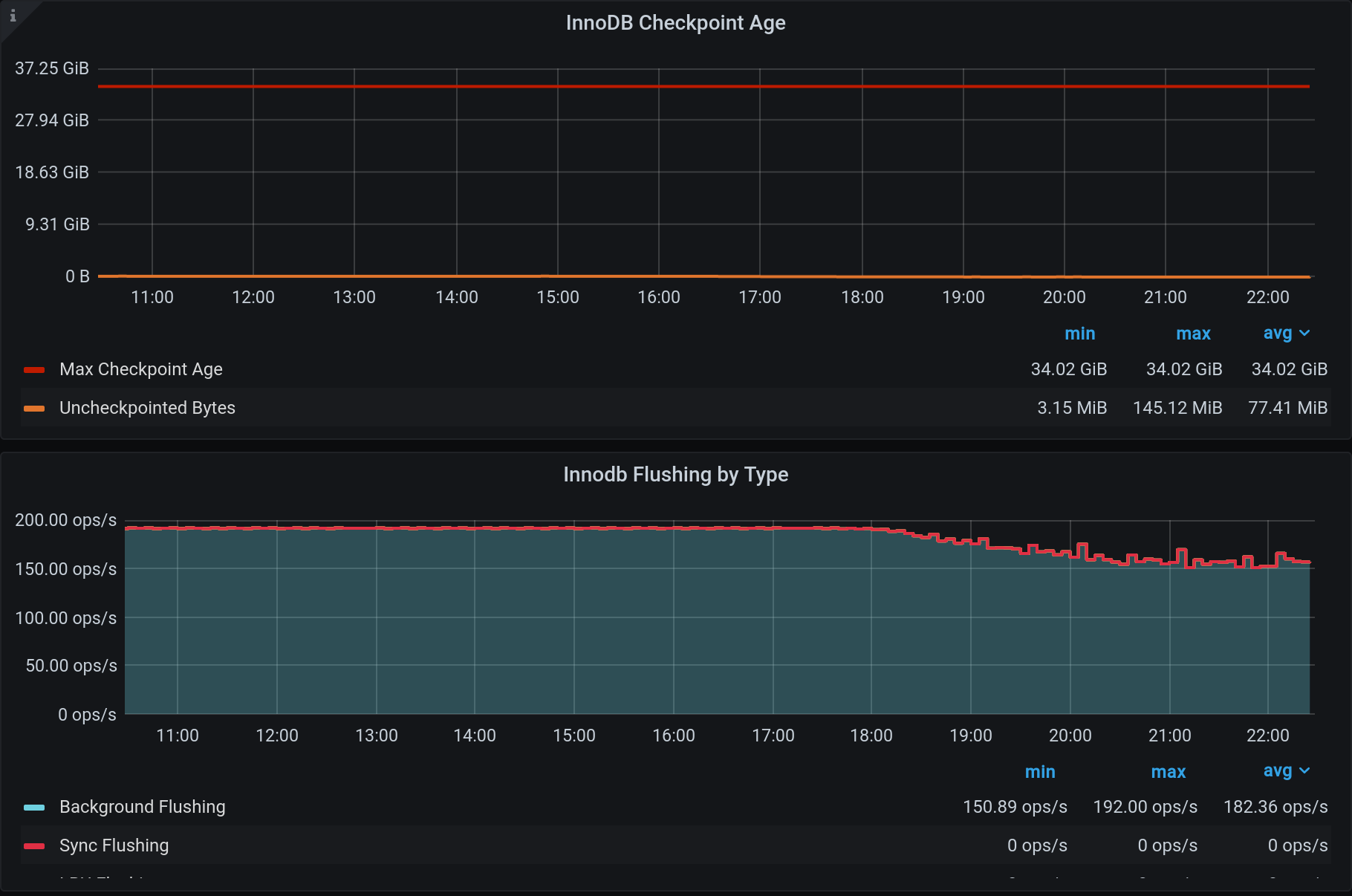
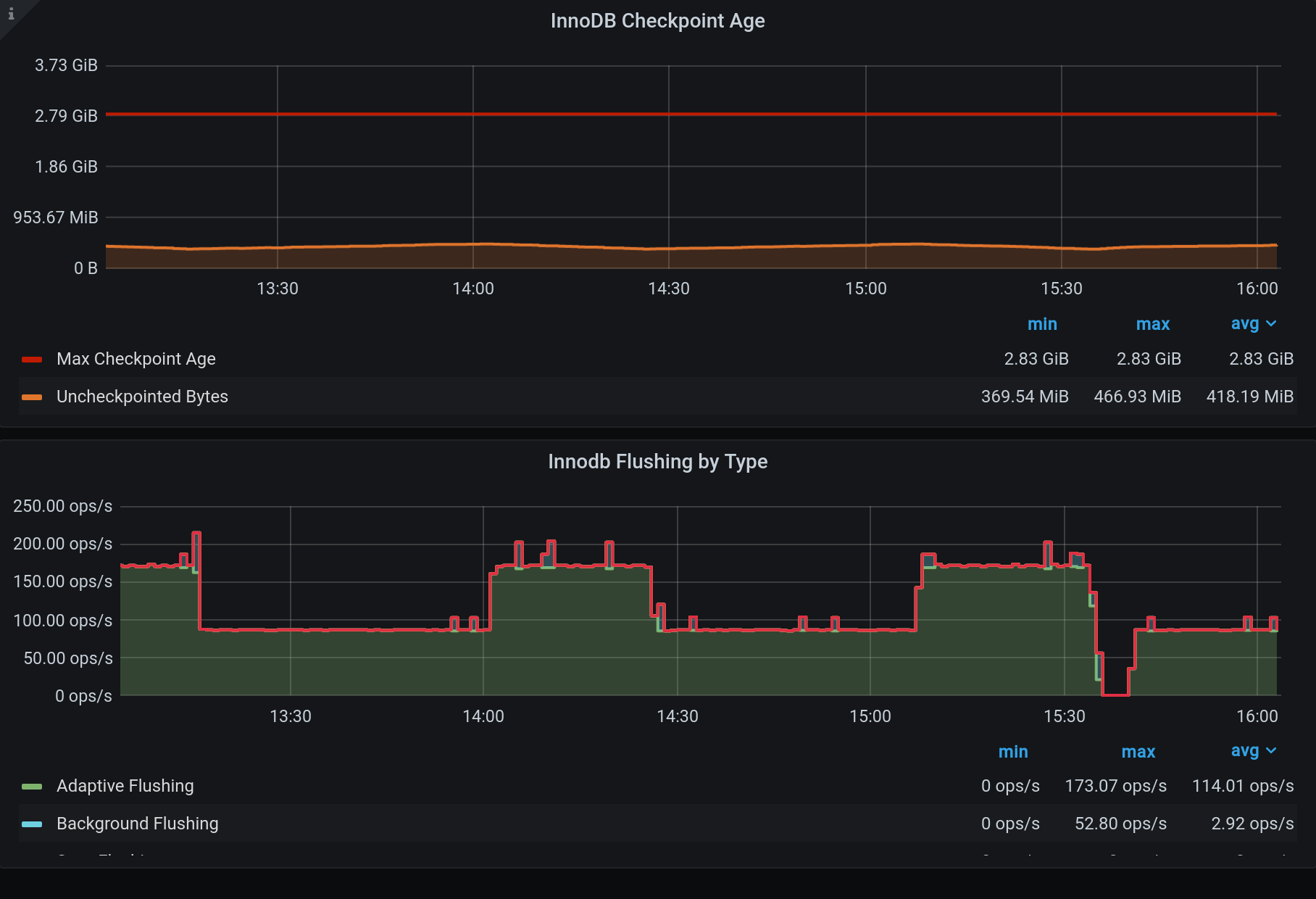
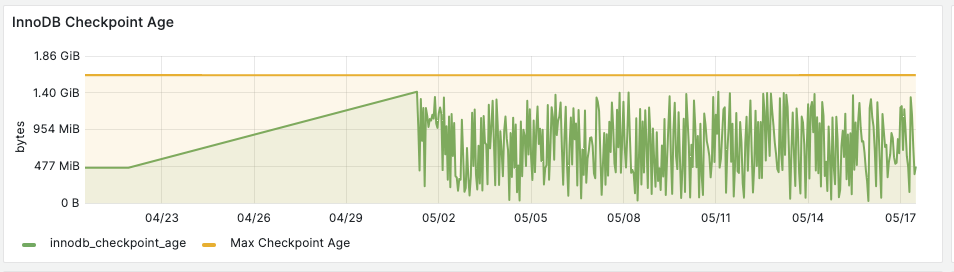
There seems to be almost no flushing whatsoever until checkpoint age reaches innodb_adaptive_flushing_lwm. Afterwards flushing goes on for several minutes, until we get to about innodb_adaptive_flushing_lwm-1% of max checkpoint age. Then flushing stops again and checkpoint age builds up to innodb_adaptive_flushing_lwm.
Expected:
I would expect adaptive flushing to happen even before lwm is hit. According to documentation:
If set to 1, the default, the server will dynamically adjust the flush rate of dirty pages in the InnoDB buffer pool. This assists to reduce brief bursts of I/O activity. If set to 0, adaptive flushing will only take place when the limit specified by innodb_adaptive_flushing_lwm is reached.
It seems to me that my instance behaves as if it was set to OFF, as adaptive flushing kicks in ONLY when lwm is reached.
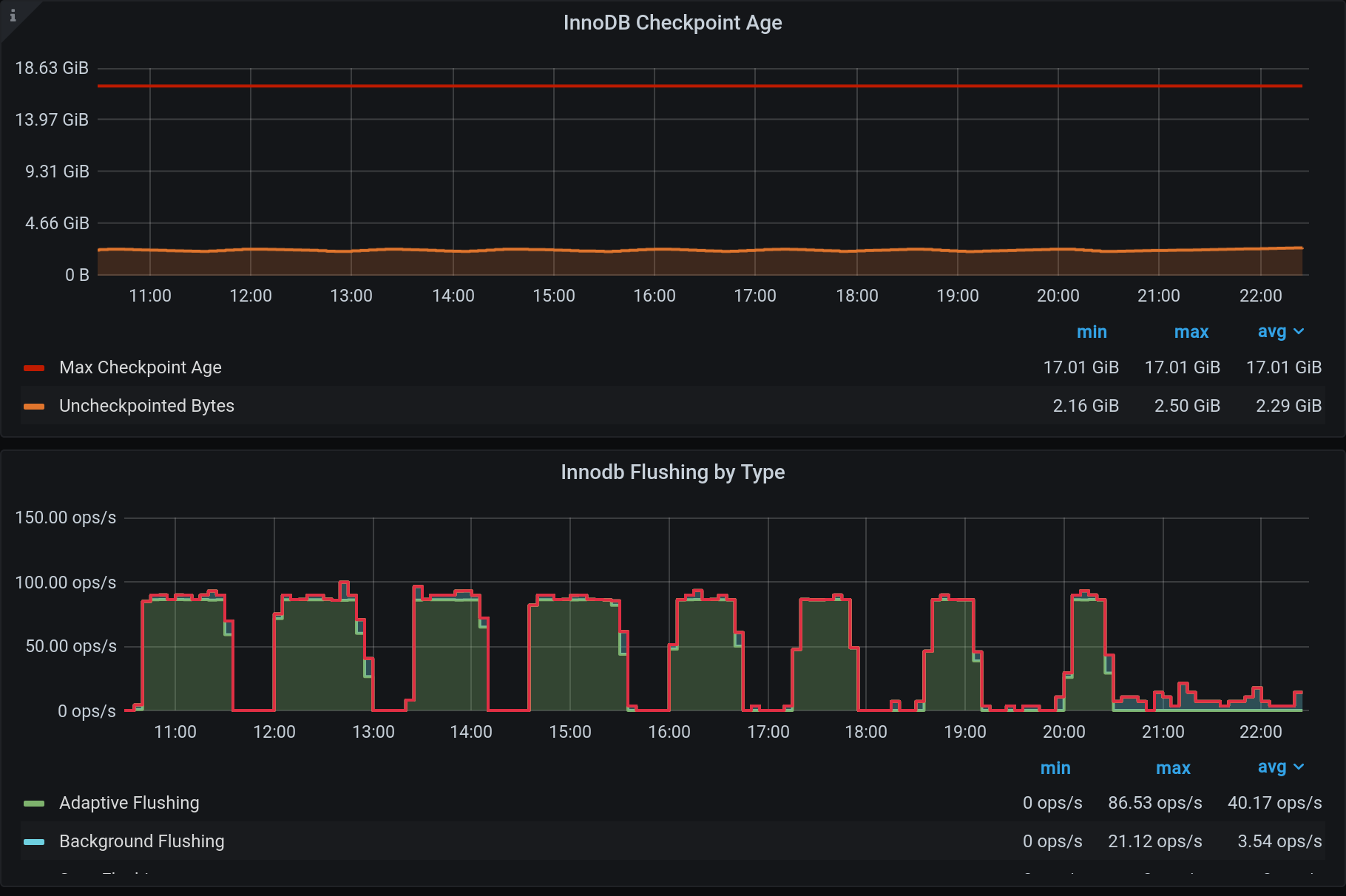
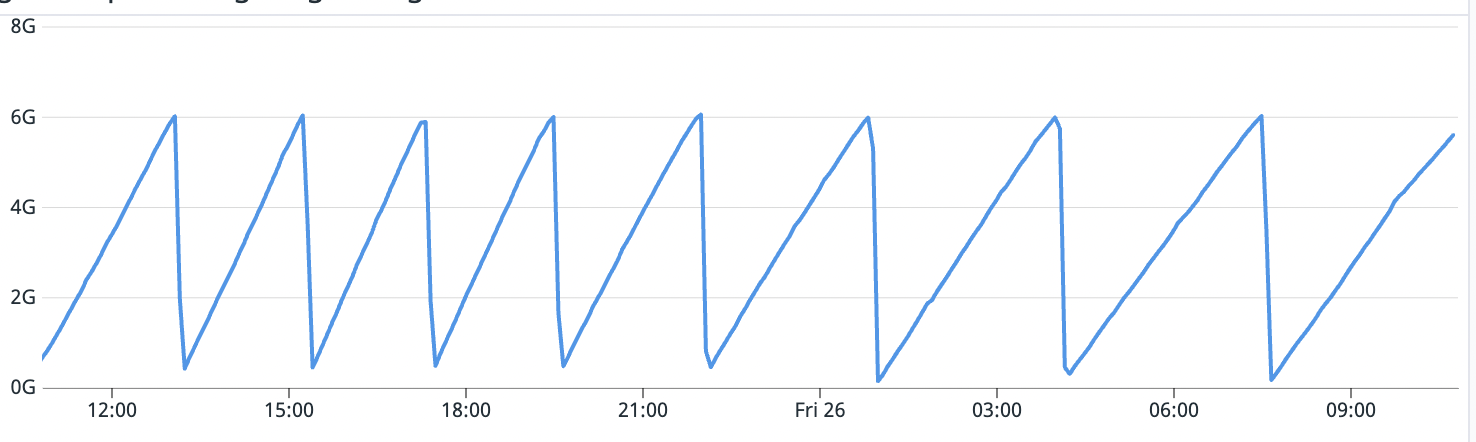
This is very different from the 10.4.15 version which has a LOT of background flushes all the time and does not actually allow any checkpoint age buildup at all. Both issues seem not optimal, but since 10.4.15 is long gone, I am opening the issue for 10.4.24. Attached screenshot of 10.4.15 is just for an idea of what it looks like on second slave, which has SAME CONFIG and SAME LOAD. Totally different behavior.
+---------------------------------------------+------------------------+
|
| Variable_name | Value |
|
+---------------------------------------------+------------------------+
|
| innodb_adaptive_flushing | ON |
|
| innodb_adaptive_flushing_lwm | 10.000000 | |
| innodb_adaptive_hash_index | OFF |
|
| innodb_adaptive_hash_index_parts | 8 | |
| innodb_flush_log_at_timeout | 1 | |
| innodb_flush_log_at_trx_commit | 2 | |
| innodb_flush_method | O_DIRECT |
|
| innodb_flush_neighbors | 0 | |
| innodb_flush_sync | ON |
|
| innodb_io_capacity | 1024 | |
| innodb_io_capacity_max | 2048 | |
| innodb_lru_scan_depth | 100 | |
| innodb_max_dirty_pages_pct | 75.000000 | |
| innodb_max_dirty_pages_pct_lwm | 0.000000 | |
+---------------------------------------------+------------------------+
|
Attachments

Issue Links
- is duplicated by
-
-
- Closed
-
- links to