Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Fixed
-
10.5.13, 10.5.21
-
None
-
SuSE Linux
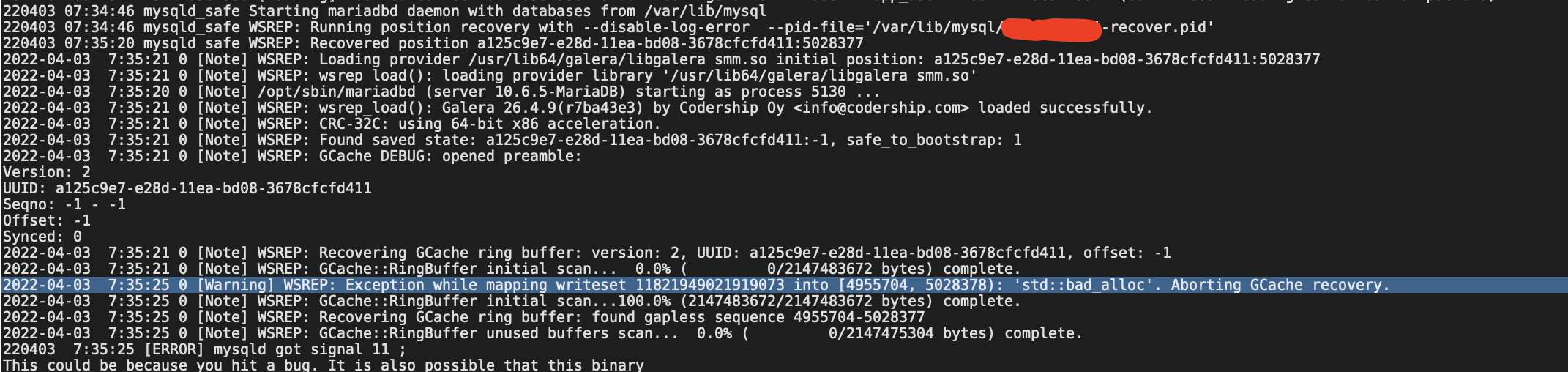
Description
Customer reports Galera ring buffer cache file seems to get corrupted in a way that the buffer size is indicated incorrectly in one of the buffer header.