Details
-
Task
-
Status: Open (View Workflow)
-
 Major
Major
-
Resolution: Unresolved
-
None
-
None
-
None
Description
The code in function calculate_cond_selectivity_for_table() faces this task:
Task setting
There is an index
INDEX key1(kp0, kp1, kp2, ...)
|
and a quick select on it. Suppose, the quick select has these properties:
- it uses N key parts.
- it produces quick_rows rows.
This gives quick select's selectivity
quick_sel= quick_rows/table_rows.
|
What we need to do: given a number K < N, compute an estimate of #rows that would be produced by a quick select built over an index that's a prefix of key1 with K key parts:
KEY key1_prefix(PREFIX({kp1, kp2, ...}, K))
|
A basic example
Suppose, the first key part kp0 has all unique rows. That is, key1 has rec_per_key[0]=1.
Then, all longer prefixes are also unique and have rec_per_key[*]=1.
Then, the selectivity of an interval
(const_l1, const_l2, ...) <= (kp0, kp1, ... ) <= (const_u1, const_u2, ....)
|
is the same as selectivity of
(const_l1) <= (kp0) <= (const_l2)
|
Reasoning: The endpoint const_l1 already uniquely identifies the position in the index, which allows records_in_range() to compute the selectivity.
const_l2 and subsequent members to not add any information.
A more general example
Look at this picture:
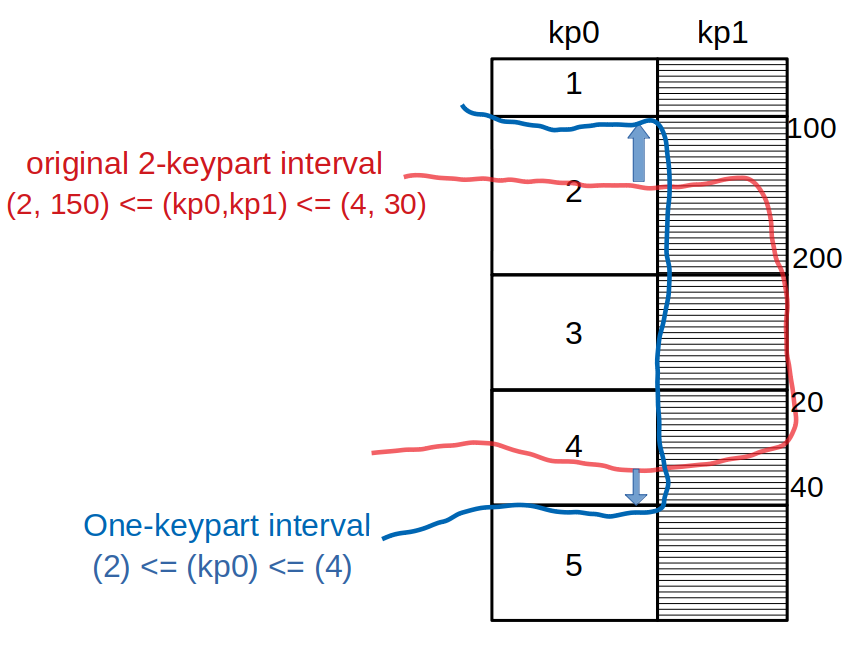
The red line denotes the original interval that is using two keyparts.
If we want to limit ourselves to one keypart, we get a wider interval, as marked in blue. The interval is extended at the front to include all values
that have kp=0. In the same way, it is extended at the back to include all values that have kp0=4.
If we make a uniformity assumption and assume that row groups with kp=0 and kp0=4 are of average size, then their size is rec_per_key[0].
We don't know which fraction of rows with kp0=2 are contained in the original interval. In the worst case, the fraction is very small and we will add almost rec_per_key[0] rows when extending the interval. The same logic applies to kp0=3.
Solution for the original task
As we have denoted earlier, using key1 gives a quick select with quick_rows rows.
If we switch to using the prefix index key1_prefix, we get the upper bound of:
quick_rows + 2*rec_per_key[K]
|
An important special case
If the quick select specifies a single-point range
(kp1, kp2, ... kpN) = (const1, ... constN)
|
then switching to a prefix of K keyparts gives us a tighter upper bound of just
rec_per_key[K]
|
.
{kind=link}