Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Not a Bug
-
10.3.22
Description
For query like this:
select * from t where (PK1, PK2, PK3) in ((v1,v2,v3), (v4,v5,v6), ...)
|
with long enough list of tuples for multi-column PK values there are 3 possible plans presented by quotes from ANALYZE FORMAT=JSON outputs):
1. Range scan, can be forced in some cases with FORCE INDEX(PRIMARY):
{
|
"query_block": {
|
"select_id": 1,
|
"r_loops": 1,
|
"r_total_time_ms": 19.184,
|
"table": {
|
"table_name": "t",
|
"access_type": "range",
|
"possible_keys": ["PRIMARY"],
|
"key": "PRIMARY",
|
"key_length": "74",
|
"used_key_parts": [
|
"PK1",
|
"PK2",
|
"PK3"
|
],
|
"r_loops": 1,
|
"rows": 1000,
|
"r_rows": 1000,
|
"r_total_time_ms": 15.165,
|
"filtered": 100,
|
"r_filtered": 100,
|
"attached_condition": "(t.PK1,t.PK2,t.PK3) in (<cache>((349,'*********','01')),<cache>((349,'*********','01')),)"
|
}
|
}
|
}
|
2. For the same IN list in other environment we end up with full table scan that is very slow:
{
|
"query_block": {
|
"select_id": 1,
|
"r_loops": 1,
|
"r_total_time_ms": 51060,
|
"table": {
|
"table_name": "t",
|
"access_type": "ALL",
|
"possible_keys": [
|
"PRIMARY",
|
...
|
],
|
"r_loops": 1,
|
"rows": 7957643,
|
"r_rows": 7.96e6,
|
"r_total_time_ms": 48324,
|
"filtered": 100,
|
"r_filtered": 0.0126,
|
"attached_condition": "(t.PK1,t.PK2,t.PK3) in (<cache>((***,'*******','01')),<cache>((***,'*******','01')),.......)"
|
}
|
}
|
}
|
3. Finally in other environment with very similar data for the same IN list we end up with semijoin optimization applied:
{
|
"query_block": {
|
"select_id": 1,
|
"r_loops": 1,
|
"r_total_time_ms": 11.565,
|
"duplicates_removal": {
|
"table": {
|
"table_name": "<derived3>",
|
"access_type": "ALL",
|
"r_loops": 1,
|
"rows": 1000,
|
"r_rows": 1000,
|
"r_total_time_ms": 0.1065,
|
"filtered": 100,
|
"r_filtered": 100,
|
"materialized": {
|
"query_block": {
|
"union_result": {
|
"table_name": "<unit3>",
|
"access_type": "ALL",
|
"r_loops": 0,
|
"r_rows": null,
|
"query_specifications": [
|
{
|
"query_block": {
|
"select_id": 3,
|
"table": {
|
"message": "No tables used"
|
}
|
}
|
}
|
]
|
}
|
}
|
}
|
},
|
"table": {
|
"table_name": "t",
|
"access_type": "eq_ref",
|
"possible_keys": [
|
"PRIMARY",
|
...
|
],
|
"key": "PRIMARY",
|
"key_length": "74",
|
"used_key_parts": [
|
"PK1",
|
"PK2",
|
"PK3"
|
],
|
"ref": ["tvc_0._col_1", "func", "func"],
|
"r_loops": 1000,
|
"rows": 1,
|
"r_rows": 0.998,
|
"r_total_time_ms": 7.7333,
|
"filtered": 100,
|
"r_filtered": 100,
|
"attached_condition": "t.PK2 = convert(tvc_0._col_2 using utf8) and t.PK3 = convert(tvc_0._col_3 using utf8)"
|
}
|
}
|
}
|
}
|
This plan is the fastest even comparing to range join, but there is no way to force it.
So, I think there is a bug when semijoin optimization is not used even when "range" is extended to full table scan as an alternative. I'd also like to have a way to force the best plan.
Attachments
Issue Links
- relates to
-
-

- Closed
-
-
-
- Closed
-
Activity
| Field | Original Value | New Value |
|---|---|---|
| Priority | Major [ 3 ] | Critical [ 2 ] |
| Fix Version/s | 10.3 [ 22126 ] | |
| Assignee | Sergei Petrunia [ psergey ] |
As we have the same query getting different plans oin different environments, it seems something else also matters, not just number of items in the IN() list.
Ok, debugging when In->Subquery conversion is done and when it is not.
The initial candidates are selected in Item_func_in::to_be_transformed_into_in_subq
The condition in that function is that the subselect must have
values_count * value_vector_len > in_subquery_conversion_threshold
|
in order to be considered a candidate.
Then, Item_func_in::in_predicate_to_in_subs_transformer does the conversion.
It may fail to do it.
The most obvious reason is the "subquery_type_allows_materialization()-style" check.
The check should pass for the query in question as key_length = 74, this is way below the limit.
... except when there is a collation mismatch.
bool Type_handler_string_result:: |
subquery_type_allows_materialization(const Item *inner, |
const Item *outer) const |
{
|
DBUG_ASSERT(inner->cmp_type() == STRING_RESULT);
|
return outer->cmp_type() == STRING_RESULT && |
outer->collation.collation == inner->collation.collation &&
|
/* |
Materialization also is unable to work when create_tmp_table() will
|
create a blob column because item->max_length is too big.
|
The following test is copied from varstring_type_handler().
|
*/
|
!inner->too_big_for_varchar();
|
}
|
| Labels | in-to-subquery |
As we have the same query getting different plans oin different environments, it seems something else also matters, not just number of items in the IN() list.
It seems, the difference between those was that one of them was 10.3.18 and the other 10.3.24. The latter included the fix for MDEV-20900, while the former did not. The patch for MDEV-20900 introduces a strict datatype/collation check, so it's totally plausible that for a certain query,
- before the
MDEV-20900, the optimizer was able to make the IN-predicate-to-subquery conversion. - After the
MDEV-20900, the optimizer was no longer able to do it.
| Link |
This issue relates to |
| Link |
This issue relates to |
MDEV-21265 is about IN-predicate-to-subquery conversion handling a broader set of column/value datatypes.
Ok, so conversion to IN-subquery didn't work. But why does the optimizer use full table scan?
Consider this case:
create table t100 ( |
pk1 int, |
pk2 varchar(10) collate utf8mb4_general_ci, |
pk3 varchar(10), |
filler varchar(100), |
PRIMARY KEY (pk1,pk2,pk3), |
KEY pk2 (pk2), |
KEY pk1 (pk1), |
KEY pk3 (pk3) |
) engine=innodb;
|
All indexes are essential.
... insert 100K rows.
explain select * from t100 |
where (pk1, pk2, pk3) in |
((1, '12345', '1'), |
(2, '12345', '1'), |
...
|
(999, '12345', '1'), |
(1000, '12345', '1')); |
produces (on 10.3.24):
id select_type table type possible_keys key key_len ref rows Extra
|
1 SIMPLE t100 ALL PRIMARY,pk2,pk1,pk3 NULL NULL NULL 90342 Using where
|
This happens, because the range optimizer reaches SEL_ARG::MAX_SEL_ARGS (=16000) limitation and aborts.
A naive logic: 1000-elements IN-list should produce ~3K SEL_ARG objects for the PK and ~1K objects for the 3 other indexes, which gives in total 3+1=4K objects.
This is not what is happening apparently. I am not sure if this a bug or some fundamental limitation.
| Attachment | a2.test [ 54105 ] |
| Status | Open [ 1 ] | In Progress [ 3 ] |
| Attachment | screenshot-1.png [ 54223 ] |
Re-trying with the customer's table definition (which has multiple indexes).
Number of SEL_ARGS alloced (note this is as counted in PARAM::alloced_sel_args, so it less than the actual number of objects allocated).
IN-list size PARAM::alloced_sel_args
|
100 2065
|
200 4165
|
300 6265
|
400 8365
|
500 10465
|
600 12565
|
700 14665
|
800 16022
|
900 16022
|
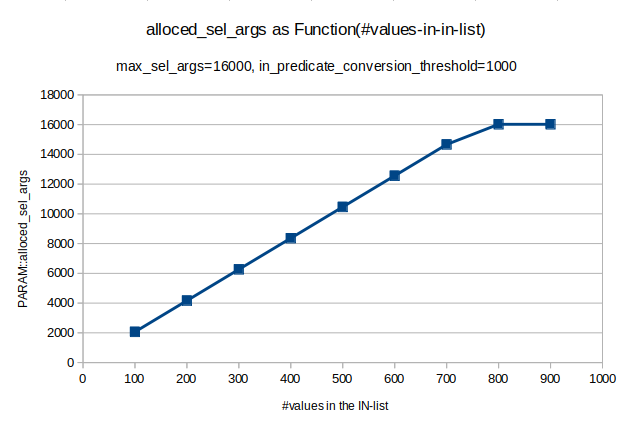
It's high but it's linear.
This is an optimizer deficiency but I won't consider this as a bug.
MariaDB's answer to very large IN-lists is IN-to-subquery conversion.
That conversion is currently limited in datatype support (as described in the linked MDEVs). This can and will be fixed as part of those MDEVs.
| Fix Version/s | N/A [ 14700 ] | |
| Fix Version/s | 10.3 [ 22126 ] | |
| Resolution | Not a Bug [ 6 ] | |
| Status | In Progress [ 3 ] | Closed [ 6 ] |
| Workflow | MariaDB v3 [ 113343 ] | MariaDB v4 [ 158356 ] |
| Zendesk Related Tickets | 184082 |
As far as I understand, the rewrite to semi-join depends purely on # of elements in the IN-list?