Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
10.3.18, 10.4.8
-
Debian Linux Buster and Stretch
Description
This issue affects Magento2 (leading eCommerce CRM): https://magento.com/
Most likely related to MDEV-12176.
Magento2 is using Entity-Attribute-Value model (EAV), also known as object-attribute-value.
with 315 tables. Here is the diagram:
https://anna.voelkl.at/magento-ce-2-1-3-database-diagram/
As a result, there are multiple "IN " statements in queries. Here is one of the problematic queries:
SELECT `main_table`.* FROM `url_rewrite` AS `main_table` WHERE (`redirect_type` = '0') AND (`entity_type` = 'product') AND (`entity_id` IN('448', '503', '532', '547 ........... <------ if the number of products here exceeds 1000, then "optimizer" creates subqueries.
In MariaDB 10.1 and 10.2 and also MySQL 8 it's a SIMPLE execution plan that takes 6 seconds:
- see screenshot 1
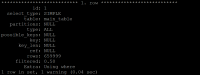
95210 rows in set (5.58 sec)
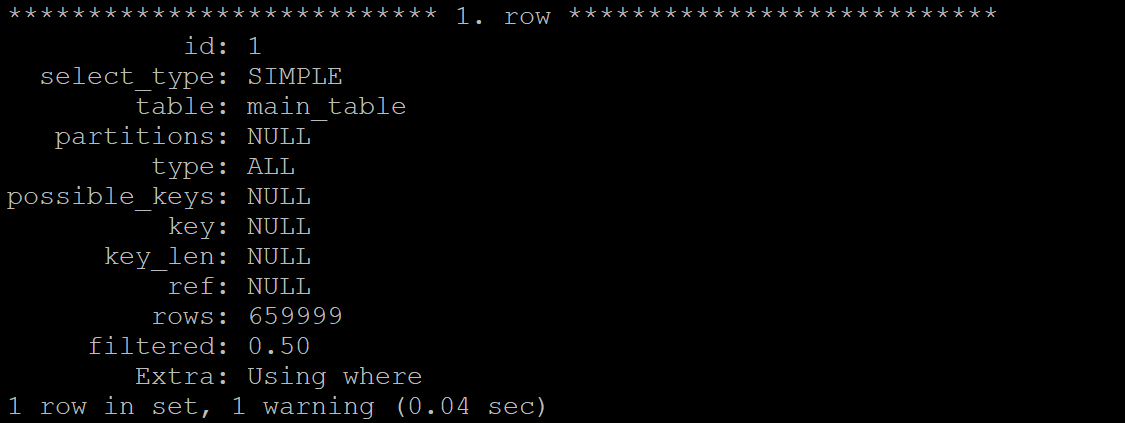
On MariaDB 10.3 and 10.4 on the same server with the same settings (including optimizer_switch) it's now 35 mins:
- see screenshot 2
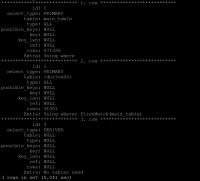

However, there is no way to disable subqueries in MDEV-12176 (@@in_predicate_conversion_threshold doesn't work on production releases)
The database is about 7GB and contains sensitive data. That's why I didn't attach it to this issue. It is available on request.
Attachments

Issue Links
- is caused by
-
MDEV-12176 Transform [NOT] IN predicate with long list of values INTO [NOT] IN subquery.
-
- Closed
-
- relates to
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
Activity
I set in_predicate_conversion_threshold to 0 in 10.3.18.
However, it didn't change the executing plan - it's exactly the same as before.
@Varun, what's the long term idea currently?
@Alex, yes it seems so that you're being hit by that issue you can take your query and trim the IN list to 999 items to be sure...
Basically in the new version some of problems related to this IN-subquery-expansion were fixed. Can't tell which ones, I have done some testing a like a month ago and some of the queries I had problems with started behaving "properly".
In my company we have developed a system to compare everything we run on 10.1 with 10.4 and in_predicate_conversion_threshold is in fact working. BUT, it seems that it can't be set in config file for newest 10.4. Maybe it is just our installation but it always reverted to default value. Try doing it "manually" and issue SET GLOBAL in_predicate_conversion_threshold = 0 in the console, and hopefully the issues will be gone
I tested it on both 10.3.18 and 10.4.8 and even though in_predicate_conversion_threshold is set to 0 in both console and in my.cnf, it has absolutely zero effect on the execution plan. I've tried initially with default options for optimizer_switch and then tried to disable flags introduced in 10.3 and 10.4 (for instance, rowid_filter=off, condition_pushdown_from_having=off, split_materialized=off, etc. ). Also, I've tried to change join_cache_level and played with join_buffer_space_limit, rowid_merge_buff_size, join_buffer_size - it had zero effect either.
Unfortunately, there is no way for me to trim the query - it's part of Magento2 CRM system (means it affects a lot of sites - it's estimated that about 35% of all the ecommerce sites are magento2 sites).
Very strange, haven't observed that... and actually this new optimization is something which would make our servers to die due to starvation within couple of minutes, so i'm preety certain it's disabled as expected ![]()
I remember that i thought it isn't working on the first try as well because when you're using SET GLOBAL you need to close the connection and open new one for it to have effect. Just after you set it try checking if it's in fact set properly to given value, if 0 won't work try setting to 4 billions instead. Maybe you're using persistent connections or connection pooling and that's why you still have issues. Stop all services, start mysql, do SET GLOBAL from console, only then start HTTP/pool.
https://www.screencast.com/t/MwgkbWQYoM
>Unfortunately, there is no way for me to trim the query
Yes, i mean to just copy it using SHOW FULL PROCESSLIST and then removing the items manually to be sure it's not something else than this in-predicate-conversion optimization...
Hello.
Thank you so much! Your suggestion worked indeed. I had to set global in_predicate_conversion_threshold = 0, exit mysql, login again and it worked (I was just using explain select to see the execution plan).
So I can confirm that settings in_predicate_conversion_threshold = 0 in my.cnf does NOT work. I really hope this can be fixed with introduction of a new optimizer_switch flag.
Hi babanski, yes it is a bug that in_predicate_coversion_threshold does not work in my.cnf file, i had just tried to do it in a session. I have fixed this and in the next release you can set this in the cnf file and it will work.
Now coming to the second part to investigate why is there such a performance difference, can you share
1) table structure of main_table (SHOW CREATE TABLE main_table)
2) if on 10.4 the output of the optimizer trace output for the query:
- set optimizer_trace=1
- EXPLAIN SELECT .....
- SELECT * from INFORMATION_SCHEMA.OPTIMIZER_TRACE
@Alex, that's great, good it helped
@Varun, if this helps you can also look at my bug report.
When you see test case 1 AFAIR it's fixed in newest 10.4, but when you go to test 2 it isn't able to use indexes. I think Alex is having same issue i reported in "test case 2" because his query looks almost the same. So computational complexity goes from O ( n ) to O ( n^2 ) in worst case as i believe something which was just more-or-less a hash lookup in 10.1 and 10.2 - is converted to nested table scan in 10.3 and 10.4...
Hi pslawek83, is the type mismatch an important use case
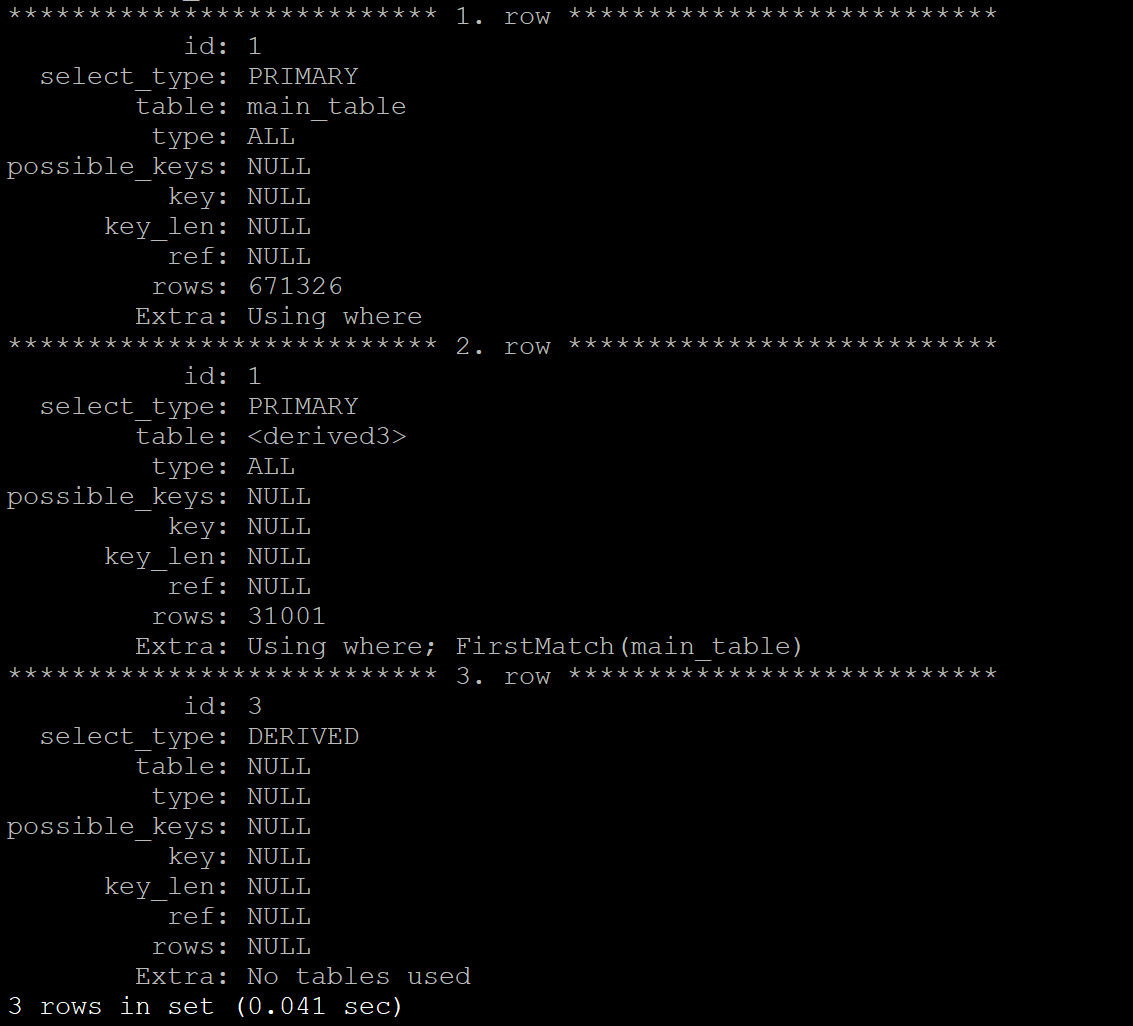
I can reproduce this with a smaller value for in_predicate_conversion_threshold
MariaDB [test]> set in_predicate_conversion_threshold=10;
|
Query OK, 0 rows affected (0.002 sec)
|
MariaDB [test]> EXPLAIN SELECT * FROM t1 WHERE id2 IN ("0","1","2","3","4","5","6","7","8","9");
|
+------+-------------+------------+------+---------------+------+---------+------+------+-----------------------------------------------------------------+
|
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|
+------+-------------+------------+------+---------------+------+---------+------+------+-----------------------------------------------------------------+
|
| 1 | PRIMARY | t1 | ALL | NULL | NULL | NULL | NULL | 100 | |
|
| 1 | PRIMARY | <derived3> | ALL | NULL | NULL | NULL | NULL | 10 | Using where; FirstMatch(t1); Using join buffer (flat, BNL join) |
|
| 3 | DERIVED | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
|
+------+-------------+------------+------+---------------+------+---------+------+------+-----------------------------------------------------------------+
|
3 rows in set (0.012 sec)
|
|
here id2 is an column with type INT, so here the types compared are INT with STRING, so here we can't have Semi join materialization as it expects the same type of the left and right hand side of the IN predicate(that got converted to a subquery).
Lets now change id2 to id3
id3 is VARCHAR(255)
MariaDB [test]> EXPLAIN SELECT * FROM t1 WHERE id3 IN ("0","1","2","3","4","5","6","7","8","9");
|
+------+--------------+-------------+--------+---------------+--------------+---------+------+------+----------------+
|
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|
+------+--------------+-------------+--------+---------------+--------------+---------+------+------+----------------+
|
| 1 | PRIMARY | t1 | ALL | NULL | NULL | NULL | NULL | 100 | |
|
| 1 | PRIMARY | <subquery2> | eq_ref | distinct_key | distinct_key | 4 | func | 1 | Using where |
|
| 2 | MATERIALIZED | <derived3> | ALL | NULL | NULL | NULL | NULL | 10 | |
|
| 3 | DERIVED | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
|
+------+--------------+-------------+--------+---------------+--------------+---------+------+------+----------------+
|
4 rows in set (0.010 sec)
|
|
so here we use Semi Join materialization and this is making a lookup so this would be either faster(depends on number of duplicates) or would be the same.
Hi @Varun thank you for looking into this. Sure, I understand. Basically as for me the deal is that we're not having any memory-usage issues related to creating these in-memory-hash (or skiplist) structures which are used "normally", so we just disabled this optimization feature altogether and all works great for us.
Not sure about @Alex, just wanted to point out that this seems to be the same issue, so you can probably "group" it with MDEV-20105 when confirmed.
Quick comment about mismatching types, we actually are using strings for everything because we found out this way is safer. Eg. we're getting something from mysql as string and then we can query using string without worrying about eg. overflowing integer range, so we just got rid of one problem for us this way, as we're using large integers sometimes ![]()
Hi pslawek83 babanski, I discussed this issue with my team and it is decided that for different types we should disable this optimization. This is done as it would need some work to allow different types for this optimization and we would not like to push that change to GA versions.
Hi Varun, that's great news because issues related to this are rather hard to diagnose. It should improve user experience a lot, if you can disable IN(...) expansion for problematic cases...
Review input: http://lists.askmonty.org/pipermail/commits/2019-December/014082.html . Small changes are needed.
Also, please file the MDEV about handling a broader set of datatype comparison and link to this MDEV.
New Patch after review addressal
http://lists.askmonty.org/pipermail/commits/2019-December/014083.html
Has also created MDEV-21265 to handle broader set of datatype comparison.
in_predicate_conversion_threshold now works on release builds too, this was fixed in https://jira.mariadb.org/browse/MDEV-16871. Should be available with 10.3.18 onwards.
You can set in_predicate_conversion_threshold to 0 to disable this optimization, this would be
a temporary workaround.