Details
-
Task
-
Status: Open (View Workflow)
-
 Major
Major
-
Resolution: Unresolved
-
None
Description
This is a followup to the discussion here:
https://www.mail-archive.com/maria-developers@lists.launchpad.net/msg11521.html
The idea is that index_merge intersection and sort-intersection can avoid scanning the ranges of rowids that do not overlap with ranges of rowids produced by other scans.
sort-intersect algorithm
The idea is:
- Start computing the intersection with the quick select that is the most selective.
- Modify the Unique object to keep min/max rowid it has seen (This can be done with very little extra overhead)
- When starting a scan on a non-first range access, attach the [min_rowid, max_rowid]
to each range.
Limitation #1: the range must use all keyparts
if an index is defined as IDX(col1, col2, col3)
Then it actually is
IDX(col1, col2, col3, rowid)
|
so ranges like
(c1min, c2min, c3min) <= (col1,col2,col3) <= (const1,const2,const3)
|
can be changed into
(c1min, c2min, c3min, MIN_ROWID) <= (col1,col2,col3, rowid) <= (const1,const2,const3, MAX_ROWID)
|
This is only possible when the range endpoints include col3. If this is not the case, we can't do that.
Limitation #2: No open endpoints
Consider a key IDX(col1) and a range:
"col1 > 10"
|
The range starts with col1=11 and does not include any rows with col1=10.
If we add the rowid, we will get
(col1, rowid) > (10, rowid_ptr)
|
which does include rows with col1=10, which will make it worse, not better.
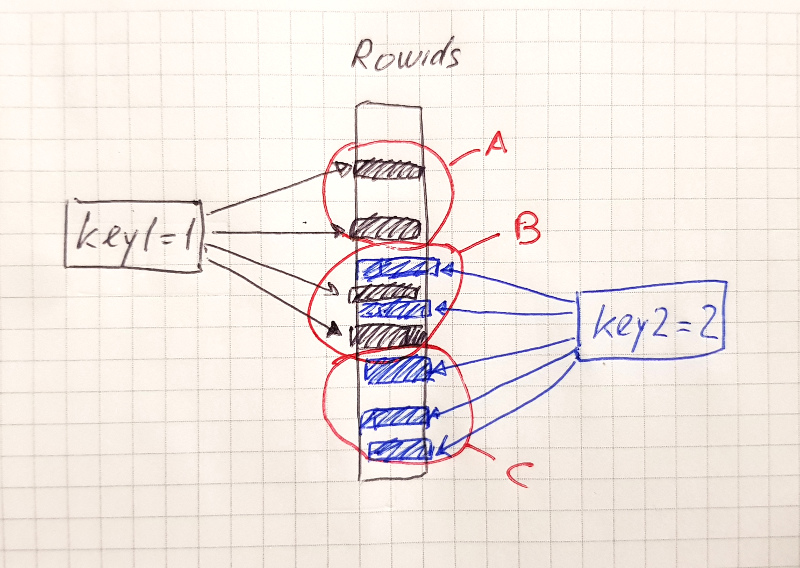
ROR-intersect algorithm
- For each select, get the first row, get its rowid. Find the biggest rowid $R_START.
- Re-start the quick select scans, adding rowid $R_START to the left bound.
ROR ranges always have the form "t.key=const" (where equalities on all key parts are present), which means
- "Range must use all keyparts" limitation is met.
- "No open endpoints" is also met.
Other issues
under what condition can SQL layer perform index reads with index lookup tuples that have rowids attached to their ends?
When the storage engine supports "Extended Keys" and there is an explicitly-defined PK. What about tables with no explicitly-defined PK?
(Q: what about partitioned tables? Is this allowed for them?)