Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Cannot Reproduce
-
10.3.7
-
centos7 64bit
Description
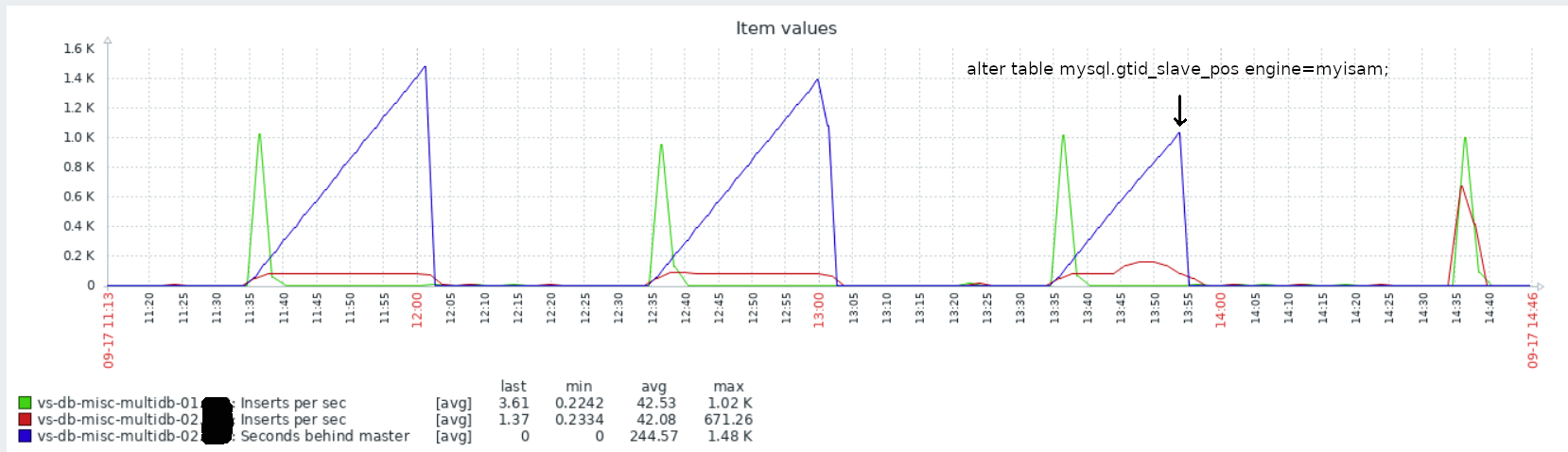
We have 2 identical slaves running, same hardware and same software.
After upgrading one of the slaves from 10.1.33 to 10.3.7 (now 48hours ago) the upgraded slave (which is set to maintenance mode, so is not receiving extra work on top of the replication) can not follow the master server. its behind and the backlog is constantly increasing.
Both servers have the exact same hardware and work fine in 10.1.33.
They are not cpu and not io bound.
Those servers never ran 10.2
99% of the tables are innodb
attached is a config diff for a show variables.
If anything else is needed, let me know