Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Not a Bug
-
10.0.34, 10.0(EOL), 10.1(EOL), 10.2(EOL), 10.3(EOL)
-
Linux
Description
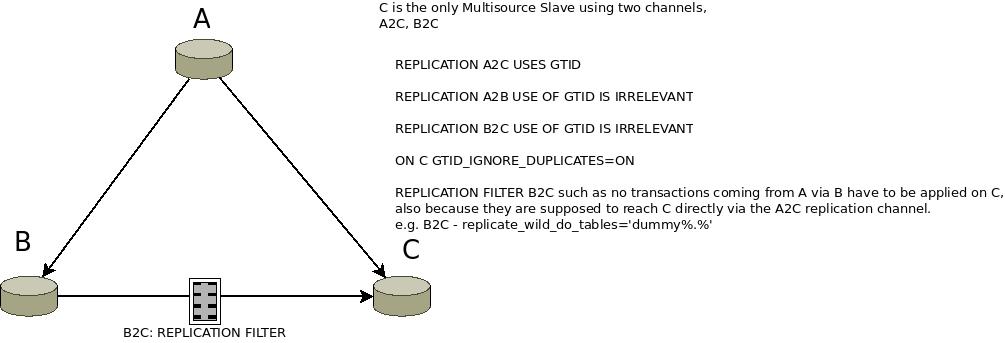
When two GTIDs get to the same Slave like for example via a multisource setup one of the two is discarded if you have gtid_ignore_duplicates=ON.
This is fine.
Also there is no guarantee on via which multisource channel each GTID arrives and it's processed first, they are all written in the per-source relay log and processed asynchronously, this is also fine.
If you have a good replication setup you probably have put in place replication filters so that duplicate transactions are not applied twice on the same slave(they still are copied from the Master into the relay logs). With GTID the option gtid_ignore_duplicates can save you, but with traditional coordinates you risk to apply twice the same transactions.
For this reason a setup that can lead the same transaction to reach to same multisource slave should have a `replication_wild_do|ignore` filter to avoid this (unless you are implementing a sort of custom highly available replication setup).
The problem happens exactly when you setup a filter, the piece of code that checks for duplicates apparently(at least from my limited understanding) is not aware that GTIDs coming from the channel with the filter won't be actually applied, so if the channel without the filter arrives second on a specific GTID it will be considered as duplicate and not applied, with the result of having missing transactions.
I attach a picture of the setup and the log of some testing I executed amending sql/rpl_gtid.cc to add some extra debug prints.
For reference: https://jira.mariadb.org/browse/MDEV-5804