Details
-
New Feature
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
6.3.1
-
None
-
2021-17
Description
PP now uses PriorityThreadPool(PTP) that has 3 priority queues and supports Job re-scheduling(can happen if there is no space to service a primitive job request from EM).
PTP doesn't equally distribute computation resources b/w primitive jobs that belongs to different queries so that the variance of query timings is linear to number of simultaneous queries.
The suggestion is to implement a scheduling component that will try to fairly process mentioned primitive jobs.
Attachments
Issue Links
- blocks
-
MCOL-4593 Multiple concurrent queries with aggregates are bottlenecked, result in lack of user scalability
-

- Stalled
-
Activity
| Rank | Ranked higher |
| Status | Open [ 1 ] | Confirmed [ 10101 ] |
| Status | Confirmed [ 10101 ] | Open [ 1 ] |
| Status | Open [ 1 ] | Confirmed [ 10101 ] |
| Assignee | Roman [ drrtuy ] |
| Status | Confirmed [ 10101 ] | In Progress [ 3 ] |
| Fix Version/s | 22.08 [ 26904 ] | |
| Fix Version/s | 6.4.1 [ 26046 ] |
| Fix Version/s | 22.08.1 [ 28206 ] | |
| Fix Version/s | 22.08 [ 26904 ] |
Here are the first benchmark setup that I run on c59xlarge AWS instance(36 cores). Dataset is flights that is available here.. There were 13 mln records(to fit everything into memory). I run a single query that hits PP harder than EM in 5 threads using sysbench(see .lua script attached). Here is the query.
select s from (select count(*) as s from flights group by tail_num)sub;
|
Here are some results(see the attached latency distribution histograms also).
develop-6, 44d326ef
General statistics:
|
total time: 54.7672s
|
total number of events: 500
|
|
|
Latency (ms):
|
min: 321.53
|
avg: 547.31
|
max: 968.99
|
95th percentile: 682.06
|
sum: 273653.81
|
|
MCOL-5044-3, 61a1242b
General statistics:
|
total time: 47.2456s
|
total number of events: 500
|
|
|
Latency (ms):
|
min: 212.46
|
avg: 471.78
|
max: 708.09
|
95th percentile: 601.29
|
sum: 235890.47
|
The total time, 95 percentile are 12% better with the fair scheduling policy.
To be precise a mixed workload doesn't have significant positive effect as a PP-heavy queries, the improvement lies within statistical error.
| Attachment | Снимок экрана от 2022-05-26 17-09-56.png [ 63933 ] |
| Attachment | Снимок экрана от 2022-05-26 17-09-56.png [ 63933 ] |
| Attachment | latency-histogram-develop-6(left)-fair-scheduler(right).png [ 63934 ] |
-fair-scheduler(right).png){kind=link}
| Sprint | 2021-17 [ 614 ] |
| Rank | Ranked higher |
The mixed workload test(slap6.lua) doesn't make a benefit so obvious though.
develop-6 run on a 16 core Xeon E5620 @ 2.40GHz
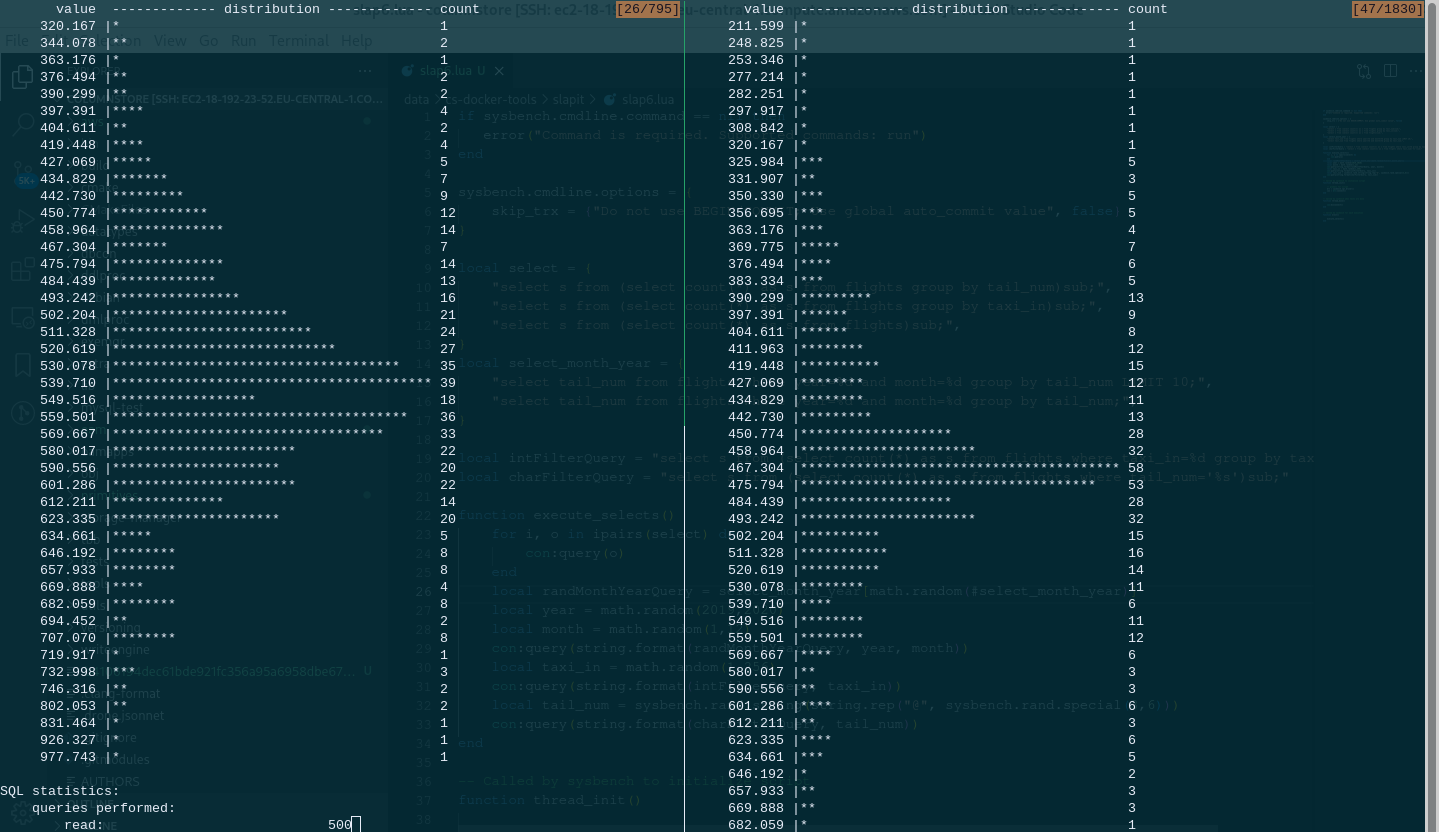
Latency histogram (values are in milliseconds)
|
value ------------- distribution ------------- count
|
3267.187 |* 1
|
3326.551 |** 2
|
3386.993 |** 2
|
3448.533 |* 1
|
3511.192 |* 1
|
3639.945 |******** 8
|
3706.081 |****** 6
|
3773.420 |******* 7
|
3841.981 |***************** 16
|
3911.789 |********************** 21
|
3982.864 |************************* 24
|
4055.231 |******************************** 30
|
4128.913 |************************************ 34
|
4203.934 |**************************************** 38
|
4280.318 |*************************** 26
|
4358.090 |********************** 21
|
4437.275 |******************* 18
|
4517.898 |************ 11
|
4599.987 |************** 13
|
4683.567 |************ 11
|
4768.666 |**** 4
|
4855.311 |* 1
|
4943.530 |* 1
|
5033.352 |* 1
|
5124.806 |* 1
|
5409.260 |* 1
|
|
SQL statistics:
|
queries performed:
|
read: 1800
|
write: 0
|
other: 0
|
total: 1800
|
transactions: 300 (0.72 per sec.)
|
queries: 1800 (4.31 per sec.)
|
ignored errors: 0 (0.00 per sec.)
|
reconnects: 0 (0.00 per sec.)
|
|
|
General statistics:
|
total time: 417.4668s
|
total number of events: 300
|
|
|
Latency (ms):
|
min: 3288.39
|
avg: 4169.14
|
max: 5418.50
|
95th percentile: 4683.57
|
sum: 1250742.04
|
|
vs MCOL-5044
Latency histogram (values are in milliseconds)
|
value ------------- distribution ------------- count
|
2362.716 |* 1
|
3511.192 |* 1
|
3574.989 |** 3
|
3639.945 |* 2
|
3706.081 |****** 8
|
3773.420 |**** 6
|
3841.981 |*********** 15
|
3911.789 |************* 17
|
3982.864 |****************** 24
|
4055.231 |************************** 35
|
4128.913 |********************************* 45
|
4203.934 |**************************************** 54
|
4280.318 |********************** 30
|
4358.090 |*********** 15
|
4437.275 |********** 13
|
4517.898 |******** 11
|
4599.987 |****** 8
|
4683.567 |**** 6
|
4768.666 |** 3
|
4855.311 |* 2
|
5124.806 |* 1
|
|
SQL statistics:
|
queries performed:
|
read: 1800
|
write: 0
|
other: 0
|
total: 1800
|
transactions: 300 (0.72 per sec.)
|
queries: 1800 (4.33 per sec.)
|
ignored errors: 0 (0.00 per sec.)
|
reconnects: 0 (0.00 per sec.)
|
|
|
General statistics:
|
total time: 416.1538s
|
total number of events: 300
|
|
|
Latency (ms):
|
min: 2381.25
|
avg: 4153.23
|
max: 5093.98
|
95th percentile: 4599.99
|
sum: 1245967.92
|
|
|
Threads fairness:
|
events (avg/stddev): 100.0000/0.00
|
execution time (avg/stddev): 415.3226/0.59
|
| Status | In Progress [ 3 ] | In Testing [ 10301 ] |
| Assignee | Roman [ drrtuy ] | Daniel Lee [ dleeyh ] |
| Assignee | Daniel Lee [ dleeyh ] | Roman [ drrtuy ] |
| Status | In Testing [ 10301 ] | Stalled [ 10000 ] |
4QA the first test goal would be to have the same functionality for single-node and cluster.
The second thing is that a delay for a small query should be smaller when PrimProcs in the cluster is busy with a complex query(or queries) that consumes the system's resource. In general I expect the current develop to increase a throughput for a mixed workload with short lasting and long lasting queries.
| Status | Stalled [ 10000 ] | Confirmed [ 10101 ] |
| Status | Confirmed [ 10101 ] | In Review [ 10002 ] |
| Status | In Review [ 10002 ] | In Testing [ 10301 ] |
| Assignee | Roman [ drrtuy ] | Daniel Lee [ dleeyh ] |
| Resolution | Fixed [ 1 ] | |
| Status | In Testing [ 10301 ] | Closed [ 6 ] |
There is a scheduling policy in the current implementation of a thread pool. It has 3 fixed priorities to allow to favor queries with a higher priority running primitive jobs in PrimProc. The scheduling policy picks a number(3 with default settings) of morsel tasks for execution out of a common queue. This scheduling doesn't fit for multiple parallel queries workload pattern b/c it tend to allocate all threads to run primitive jobs that belongs to a query that reaches PP first.
The main idea is to replace existing scheduler policy AKA thread pool with a fair scheduling policy. Here is the model:
FairThreadPool picks a primitive job that belongs to a transaction with a lowest combined cost of completed primitive jobs. (Who wants tech details about the implementation plz look at the commits)