Details
-
Bug
-
Status: Closed (View Workflow)
-
 Blocker
Blocker
-
Resolution: Not a Bug
-
2.2.1
-
None
Description
I am using the following
- AWS Aurora MySQL 5.6
- mariadb-java-client 2.2.1
- springframework 4.3.16
I am currently using fetchsize of 1000 in JdbcTemplate. For large size tables, when using select queries, I am experiencing OOM. I could confirm that Spring is able to propagate the fetchSize to the driver.
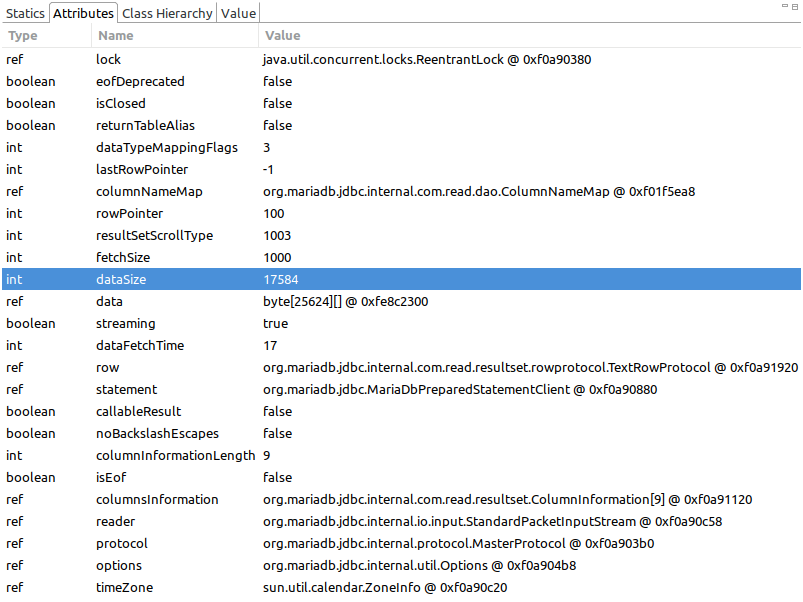
When I started debugging, I found the following observation in SelectResultSet in the driver code. When fetchSize > 0, the execution flow proceeds like
- nextStreamingValue
- addStreamingValue
- readNextValue
- growDataArray
So essentially, SelectResultSet data variable keeps growing when next is called on the ResultSet. So OOM is ought to happen eventually. BTW, I am using the default TYPE_FORWARD_ONLY scroll type.
Could anyone confirm if my understanding is correct? Is there a way to query large datasets without OOM?
Attachments
Issue Links
- relates to
-
-
- Closed
-