Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Fixed
-
10.4.18
-
None
-
CentOS 7.8
Description
Hi,
I have a setup with 3 Galera nodes on MariaDB 10.4.18.
I have blocking issue with MariaDB stability during network fluctuations (this usually happens for me when my client performs network interventions of it has hardware issues on the network).
The issues is the following:
1. After few ups and downs of the network, on single node, Galera cluster goes into a complete freeze.
2. The node that lost connection is OK, as it doe not receive traffic anymore
3 The other 2 nodes are accessible via mysql connection with root account but when I check the process list in MariaDB I have always the following query hanged updating: DELETE FROM mysql.wsrep_cluster.
- I see other queries after this, but they all have the time lower than "DELETE FROM mysql.wsrep_cluster", which makes me thing that this query somehow locks the whole database and the other queries are waiting for it. Unfortunately it never ends.
Logs analysis:
1. We do not see any slow log for the query that hangs
2. We do not see any error in MariaDB / Galera error log
In order to replicate this we perform the following test:
1. Start Galera on 3 nodes
2. We have a webservice that connects to Galera start a tool that sends queries continuously to the database
3. We perform successive ifup / ifdown at about 60 seconds interval on single node
4. After 10 -15 tries, the cluster hangs in the situation above
I'm attaching the script that we use for ifup / ifdown testing and also I'm putting here he Galera configuration:
#Galera Provider Configuration
|
wsrep_on=ON
|
wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so |
|
|
#Galera Cluster Configuration
|
wsrep_cluster_name="<EDITED>" |
wsrep_cluster_address="gcomm://<EDITED>" |
|
|
#Galera Synchronization Configuration
|
wsrep_sst_method=rsync
|
|
|
#Galera Node Configuration
|
wsrep_node_address="<EDITED>" |
wsrep_node_name="<EDITED>" |
wsrep_slave_threads = 8 |
|
|
wsrep_provider_options="gcache.size = 2G; gcache.page_size = 1G; gcs.fc_limit = 256; gcs.fc_factor = 0.99; cert.log_conflicts = ON;" |
|
|
#read consistency
|
wsrep_sync_wait=3 |
wsrep_retry_autocommit = 1 |
|
|
wsrep_debug = 1 |
wsrep_log_conflicts = 1 |
Attachments

Issue Links
- duplicates
-
-

- Closed
-
- relates to
-
-

- Closed
-
Activity
| Field | Original Value | New Value |
|---|---|---|
| Description |
Hi,
I have a setup with 3 Galera nodes on MariaDB 10.4.18. I have blocking issue with MariaDB stability during network fluctuations (this usually happens for me when my client performs network interventions of it has hardware issues on the network). The issues is the following: 1. After few ups and downs of the network, on single node, Galera cluster goes into a complete freeze. 2. The node that lost connection is OK, as it doe not receive traffic anymore 3 The other 2 nodes are accessible via mysql connection with root account but when I check the process list in MariaDB I have always the following query hanged updating: *DELETE FROM mysql.wsrep_cluster*. - I see other queries after this, but they all have the time lower than "DELETE FROM mysql.wsrep_cluster", which makes me thing that this query somehow locks the whole database and the other queries are waiting for it. Unfortunately it never ends. In order to replicate this we perform the following test: 1. Start Galera on 3 nodes 2. We have a webservice that connects to Galera start a tool that sends queries continuously to the database 3. We perform successive ifup / ifdown at about 60 seconds interval on single node 4. After 10 -15 tries, the cluster hangs in the situation above I'm attaching the script that we use for ifup / ifdown testing and also I'm putting here he Galera configuration: # Galera Provider Configuration wsrep_on=ON wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so # Galera Cluster Configuration wsrep_cluster_name="<EDITED>" wsrep_cluster_address="gcomm://<EDITED>" # Galera Synchronization Configuration wsrep_sst_method=rsync # Galera Node Configuration wsrep_node_address="<EDITED>" wsrep_node_name="<EDITED>" wsrep_slave_threads = 8 wsrep_provider_options="gcache.size = 2G; gcache.page_size = 1G; gcs.fc_limit = 256; gcs.fc_factor = 0.99; cert.log_conflicts = ON;" #read consistency wsrep_sync_wait=3 wsrep_retry_autocommit = 1 wsrep_debug = 1 wsrep_log_conflicts = 1 |
Hi,
I have a setup with 3 Galera nodes on MariaDB 10.4.18. I have blocking issue with MariaDB stability during network fluctuations (this usually happens for me when my client performs network interventions of it has hardware issues on the network). The issues is the following: 1. After few ups and downs of the network, on single node, Galera cluster goes into a complete freeze. 2. The node that lost connection is OK, as it doe not receive traffic anymore 3 The other 2 nodes are accessible via mysql connection with root account but when I check the process list in MariaDB I have always the following query hanged updating: *DELETE FROM mysql.wsrep_cluster*. - I see other queries after this, but they all have the time lower than "DELETE FROM mysql.wsrep_cluster", which makes me thing that this query somehow locks the whole database and the other queries are waiting for it. Unfortunately it never ends. In order to replicate this we perform the following test: 1. Start Galera on 3 nodes 2. We have a webservice that connects to Galera start a tool that sends queries continuously to the database 3. We perform successive ifup / ifdown at about 60 seconds interval on single node 4. After 10 -15 tries, the cluster hangs in the situation above I'm attaching the script that we use for ifup / ifdown testing and also I'm putting here he Galera configuration: #Galera Provider Configuration wsrep_on=ON wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so #Galera Cluster Configuration wsrep_cluster_name="<EDITED>" wsrep_cluster_address="gcomm://<EDITED>" #Galera Synchronization Configuration wsrep_sst_method=rsync #Galera Node Configuration wsrep_node_address="<EDITED>" wsrep_node_name="<EDITED>" wsrep_slave_threads = 8 wsrep_provider_options="gcache.size = 2G; gcache.page_size = 1G; gcs.fc_limit = 256; gcs.fc_factor = 0.99; cert.log_conflicts = ON;" #read consistency wsrep_sync_wait=3 wsrep_retry_autocommit = 1 wsrep_debug = 1 wsrep_log_conflicts = 1 |
| Description |
Hi,
I have a setup with 3 Galera nodes on MariaDB 10.4.18. I have blocking issue with MariaDB stability during network fluctuations (this usually happens for me when my client performs network interventions of it has hardware issues on the network). The issues is the following: 1. After few ups and downs of the network, on single node, Galera cluster goes into a complete freeze. 2. The node that lost connection is OK, as it doe not receive traffic anymore 3 The other 2 nodes are accessible via mysql connection with root account but when I check the process list in MariaDB I have always the following query hanged updating: *DELETE FROM mysql.wsrep_cluster*. - I see other queries after this, but they all have the time lower than "DELETE FROM mysql.wsrep_cluster", which makes me thing that this query somehow locks the whole database and the other queries are waiting for it. Unfortunately it never ends. In order to replicate this we perform the following test: 1. Start Galera on 3 nodes 2. We have a webservice that connects to Galera start a tool that sends queries continuously to the database 3. We perform successive ifup / ifdown at about 60 seconds interval on single node 4. After 10 -15 tries, the cluster hangs in the situation above I'm attaching the script that we use for ifup / ifdown testing and also I'm putting here he Galera configuration: #Galera Provider Configuration wsrep_on=ON wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so #Galera Cluster Configuration wsrep_cluster_name="<EDITED>" wsrep_cluster_address="gcomm://<EDITED>" #Galera Synchronization Configuration wsrep_sst_method=rsync #Galera Node Configuration wsrep_node_address="<EDITED>" wsrep_node_name="<EDITED>" wsrep_slave_threads = 8 wsrep_provider_options="gcache.size = 2G; gcache.page_size = 1G; gcs.fc_limit = 256; gcs.fc_factor = 0.99; cert.log_conflicts = ON;" #read consistency wsrep_sync_wait=3 wsrep_retry_autocommit = 1 wsrep_debug = 1 wsrep_log_conflicts = 1 |
Hi,
I have a setup with 3 Galera nodes on MariaDB 10.4.18. I have blocking issue with MariaDB stability during network fluctuations (this usually happens for me when my client performs network interventions of it has hardware issues on the network). The issues is the following: 1. After few ups and downs of the network, on single node, Galera cluster goes into a complete freeze. 2. The node that lost connection is OK, as it doe not receive traffic anymore 3 The other 2 nodes are accessible via mysql connection with root account but when I check the process list in MariaDB I have always the following query hanged updating: *DELETE FROM mysql.wsrep_cluster*. - I see other queries after this, but they all have the time lower than "DELETE FROM mysql.wsrep_cluster", which makes me thing that this query somehow locks the whole database and the other queries are waiting for it. Unfortunately it never ends. +In order to replicate this we perform the following test+: 1. Start Galera on 3 nodes 2. We have a webservice that connects to Galera start a tool that sends queries continuously to the database 3. We perform successive ifup / ifdown at about 60 seconds interval on single node 4. After 10 -15 tries, the cluster hangs in the situation above I'm attaching the script that we use for ifup / ifdown testing and also I'm putting here he Galera configuration: #Galera Provider Configuration wsrep_on=ON wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so #Galera Cluster Configuration wsrep_cluster_name="<EDITED>" wsrep_cluster_address="gcomm://<EDITED>" #Galera Synchronization Configuration wsrep_sst_method=rsync #Galera Node Configuration wsrep_node_address="<EDITED>" wsrep_node_name="<EDITED>" wsrep_slave_threads = 8 wsrep_provider_options="gcache.size = 2G; gcache.page_size = 1G; gcs.fc_limit = 256; gcs.fc_factor = 0.99; cert.log_conflicts = ON;" #read consistency wsrep_sync_wait=3 wsrep_retry_autocommit = 1 wsrep_debug = 1 wsrep_log_conflicts = 1 |
| Description |
Hi,
I have a setup with 3 Galera nodes on MariaDB 10.4.18. I have blocking issue with MariaDB stability during network fluctuations (this usually happens for me when my client performs network interventions of it has hardware issues on the network). The issues is the following: 1. After few ups and downs of the network, on single node, Galera cluster goes into a complete freeze. 2. The node that lost connection is OK, as it doe not receive traffic anymore 3 The other 2 nodes are accessible via mysql connection with root account but when I check the process list in MariaDB I have always the following query hanged updating: *DELETE FROM mysql.wsrep_cluster*. - I see other queries after this, but they all have the time lower than "DELETE FROM mysql.wsrep_cluster", which makes me thing that this query somehow locks the whole database and the other queries are waiting for it. Unfortunately it never ends. +In order to replicate this we perform the following test+: 1. Start Galera on 3 nodes 2. We have a webservice that connects to Galera start a tool that sends queries continuously to the database 3. We perform successive ifup / ifdown at about 60 seconds interval on single node 4. After 10 -15 tries, the cluster hangs in the situation above I'm attaching the script that we use for ifup / ifdown testing and also I'm putting here he Galera configuration: #Galera Provider Configuration wsrep_on=ON wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so #Galera Cluster Configuration wsrep_cluster_name="<EDITED>" wsrep_cluster_address="gcomm://<EDITED>" #Galera Synchronization Configuration wsrep_sst_method=rsync #Galera Node Configuration wsrep_node_address="<EDITED>" wsrep_node_name="<EDITED>" wsrep_slave_threads = 8 wsrep_provider_options="gcache.size = 2G; gcache.page_size = 1G; gcs.fc_limit = 256; gcs.fc_factor = 0.99; cert.log_conflicts = ON;" #read consistency wsrep_sync_wait=3 wsrep_retry_autocommit = 1 wsrep_debug = 1 wsrep_log_conflicts = 1 |
Hi,
I have a setup with 3 Galera nodes on MariaDB 10.4.18. I have blocking issue with MariaDB stability during network fluctuations (this usually happens for me when my client performs network interventions of it has hardware issues on the network). The issues is the following: 1. After few ups and downs of the network, on single node, Galera cluster goes into a complete freeze. 2. The node that lost connection is OK, as it doe not receive traffic anymore 3 The other 2 nodes are accessible via mysql connection with root account but when I check the process list in MariaDB I have always the following query hanged updating: *DELETE FROM mysql.wsrep_cluster*. - I see other queries after this, but they all have the time lower than "DELETE FROM mysql.wsrep_cluster", which makes me thing that this query somehow locks the whole database and the other queries are waiting for it. Unfortunately it never ends. Logs analysis: 1. We do not see any slow log query for th query that hangs 2. We do not see any error in MariaDB / Galera error log +In order to replicate this we perform the following test+: 1. Start Galera on 3 nodes 2. We have a webservice that connects to Galera start a tool that sends queries continuously to the database 3. We perform successive ifup / ifdown at about 60 seconds interval on single node 4. After 10 -15 tries, the cluster hangs in the situation above I'm attaching the script that we use for ifup / ifdown testing and also I'm putting here he Galera configuration: #Galera Provider Configuration wsrep_on=ON wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so #Galera Cluster Configuration wsrep_cluster_name="<EDITED>" wsrep_cluster_address="gcomm://<EDITED>" #Galera Synchronization Configuration wsrep_sst_method=rsync #Galera Node Configuration wsrep_node_address="<EDITED>" wsrep_node_name="<EDITED>" wsrep_slave_threads = 8 wsrep_provider_options="gcache.size = 2G; gcache.page_size = 1G; gcs.fc_limit = 256; gcs.fc_factor = 0.99; cert.log_conflicts = ON;" #read consistency wsrep_sync_wait=3 wsrep_retry_autocommit = 1 wsrep_debug = 1 wsrep_log_conflicts = 1 |
| Description |
Hi,
I have a setup with 3 Galera nodes on MariaDB 10.4.18. I have blocking issue with MariaDB stability during network fluctuations (this usually happens for me when my client performs network interventions of it has hardware issues on the network). The issues is the following: 1. After few ups and downs of the network, on single node, Galera cluster goes into a complete freeze. 2. The node that lost connection is OK, as it doe not receive traffic anymore 3 The other 2 nodes are accessible via mysql connection with root account but when I check the process list in MariaDB I have always the following query hanged updating: *DELETE FROM mysql.wsrep_cluster*. - I see other queries after this, but they all have the time lower than "DELETE FROM mysql.wsrep_cluster", which makes me thing that this query somehow locks the whole database and the other queries are waiting for it. Unfortunately it never ends. Logs analysis: 1. We do not see any slow log query for th query that hangs 2. We do not see any error in MariaDB / Galera error log +In order to replicate this we perform the following test+: 1. Start Galera on 3 nodes 2. We have a webservice that connects to Galera start a tool that sends queries continuously to the database 3. We perform successive ifup / ifdown at about 60 seconds interval on single node 4. After 10 -15 tries, the cluster hangs in the situation above I'm attaching the script that we use for ifup / ifdown testing and also I'm putting here he Galera configuration: #Galera Provider Configuration wsrep_on=ON wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so #Galera Cluster Configuration wsrep_cluster_name="<EDITED>" wsrep_cluster_address="gcomm://<EDITED>" #Galera Synchronization Configuration wsrep_sst_method=rsync #Galera Node Configuration wsrep_node_address="<EDITED>" wsrep_node_name="<EDITED>" wsrep_slave_threads = 8 wsrep_provider_options="gcache.size = 2G; gcache.page_size = 1G; gcs.fc_limit = 256; gcs.fc_factor = 0.99; cert.log_conflicts = ON;" #read consistency wsrep_sync_wait=3 wsrep_retry_autocommit = 1 wsrep_debug = 1 wsrep_log_conflicts = 1 |
Hi,
I have a setup with 3 Galera nodes on MariaDB 10.4.18. I have blocking issue with MariaDB stability during network fluctuations (this usually happens for me when my client performs network interventions of it has hardware issues on the network). The issues is the following: 1. After few ups and downs of the network, on single node, Galera cluster goes into a complete freeze. 2. The node that lost connection is OK, as it doe not receive traffic anymore 3 The other 2 nodes are accessible via mysql connection with root account but when I check the process list in MariaDB I have always the following query hanged updating: *DELETE FROM mysql.wsrep_cluster*. - I see other queries after this, but they all have the time lower than "DELETE FROM mysql.wsrep_cluster", which makes me thing that this query somehow locks the whole database and the other queries are waiting for it. Unfortunately it never ends. Logs analysis: 1. We do not see any slow log for the query that hangs 2. We do not see any error in MariaDB / Galera error log +In order to replicate this we perform the following test+: 1. Start Galera on 3 nodes 2. We have a webservice that connects to Galera start a tool that sends queries continuously to the database 3. We perform successive ifup / ifdown at about 60 seconds interval on single node 4. After 10 -15 tries, the cluster hangs in the situation above I'm attaching the script that we use for ifup / ifdown testing and also I'm putting here he Galera configuration: #Galera Provider Configuration wsrep_on=ON wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so #Galera Cluster Configuration wsrep_cluster_name="<EDITED>" wsrep_cluster_address="gcomm://<EDITED>" #Galera Synchronization Configuration wsrep_sst_method=rsync #Galera Node Configuration wsrep_node_address="<EDITED>" wsrep_node_name="<EDITED>" wsrep_slave_threads = 8 wsrep_provider_options="gcache.size = 2G; gcache.page_size = 1G; gcs.fc_limit = 256; gcs.fc_factor = 0.99; cert.log_conflicts = ON;" #read consistency wsrep_sync_wait=3 wsrep_retry_autocommit = 1 wsrep_debug = 1 wsrep_log_conflicts = 1 |
| Description |
Hi,
I have a setup with 3 Galera nodes on MariaDB 10.4.18. I have blocking issue with MariaDB stability during network fluctuations (this usually happens for me when my client performs network interventions of it has hardware issues on the network). The issues is the following: 1. After few ups and downs of the network, on single node, Galera cluster goes into a complete freeze. 2. The node that lost connection is OK, as it doe not receive traffic anymore 3 The other 2 nodes are accessible via mysql connection with root account but when I check the process list in MariaDB I have always the following query hanged updating: *DELETE FROM mysql.wsrep_cluster*. - I see other queries after this, but they all have the time lower than "DELETE FROM mysql.wsrep_cluster", which makes me thing that this query somehow locks the whole database and the other queries are waiting for it. Unfortunately it never ends. Logs analysis: 1. We do not see any slow log for the query that hangs 2. We do not see any error in MariaDB / Galera error log +In order to replicate this we perform the following test+: 1. Start Galera on 3 nodes 2. We have a webservice that connects to Galera start a tool that sends queries continuously to the database 3. We perform successive ifup / ifdown at about 60 seconds interval on single node 4. After 10 -15 tries, the cluster hangs in the situation above I'm attaching the script that we use for ifup / ifdown testing and also I'm putting here he Galera configuration: #Galera Provider Configuration wsrep_on=ON wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so #Galera Cluster Configuration wsrep_cluster_name="<EDITED>" wsrep_cluster_address="gcomm://<EDITED>" #Galera Synchronization Configuration wsrep_sst_method=rsync #Galera Node Configuration wsrep_node_address="<EDITED>" wsrep_node_name="<EDITED>" wsrep_slave_threads = 8 wsrep_provider_options="gcache.size = 2G; gcache.page_size = 1G; gcs.fc_limit = 256; gcs.fc_factor = 0.99; cert.log_conflicts = ON;" #read consistency wsrep_sync_wait=3 wsrep_retry_autocommit = 1 wsrep_debug = 1 wsrep_log_conflicts = 1 |
Hi,
I have a setup with 3 Galera nodes on MariaDB 10.4.18. I have blocking issue with MariaDB stability during network fluctuations (this usually happens for me when my client performs network interventions of it has hardware issues on the network). The issues is the following: 1. After few ups and downs of the network, on single node, Galera cluster goes into a complete freeze. 2. The node that lost connection is OK, as it doe not receive traffic anymore 3 The other 2 nodes are accessible via mysql connection with root account but when I check the process list in MariaDB I have always the following query hanged updating: *DELETE FROM mysql.wsrep_cluster*. - I see other queries after this, but they all have the time lower than "DELETE FROM mysql.wsrep_cluster", which makes me thing that this query somehow locks the whole database and the other queries are waiting for it. Unfortunately it never ends. Logs analysis: 1. We do not see any slow log for the query that hangs 2. We do not see any error in MariaDB / Galera error log +In order to replicate this we perform the following test+: 1. Start Galera on 3 nodes 2. We have a webservice that connects to Galera start a tool that sends queries continuously to the database 3. We perform successive ifup / ifdown at about 60 seconds interval on single node 4. After 10 -15 tries, the cluster hangs in the situation above I'm attaching the script that we use for ifup / ifdown testing and also I'm putting here he Galera configuration: {code:java} #Galera Provider Configuration wsrep_on=ON wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so #Galera Cluster Configuration wsrep_cluster_name="<EDITED>" wsrep_cluster_address="gcomm://<EDITED>" #Galera Synchronization Configuration wsrep_sst_method=rsync #Galera Node Configuration wsrep_node_address="<EDITED>" wsrep_node_name="<EDITED>" wsrep_slave_threads = 8 wsrep_provider_options="gcache.size = 2G; gcache.page_size = 1G; gcs.fc_limit = 256; gcs.fc_factor = 0.99; cert.log_conflicts = ON;" #read consistency wsrep_sync_wait=3 wsrep_retry_autocommit = 1 wsrep_debug = 1 wsrep_log_conflicts = 1 {code} |
| Priority | Blocker [ 1 ] | Major [ 3 ] |
| Attachment | MariaDB valication diagram.png [ 58030 ] |
| Attachment | Galera Log - ETH-UP-Down-OK.txt [ 58031 ] |
| Attachment | MariaDB-server.cnf [ 58032 ] |
| Attachment | Galera Log - ETH-UP-Down-FAIL.txt [ 58033 ] |
| Attachment | MariaDB-Log.png [ 58034 ] |
Hi,
Thanks for your response,
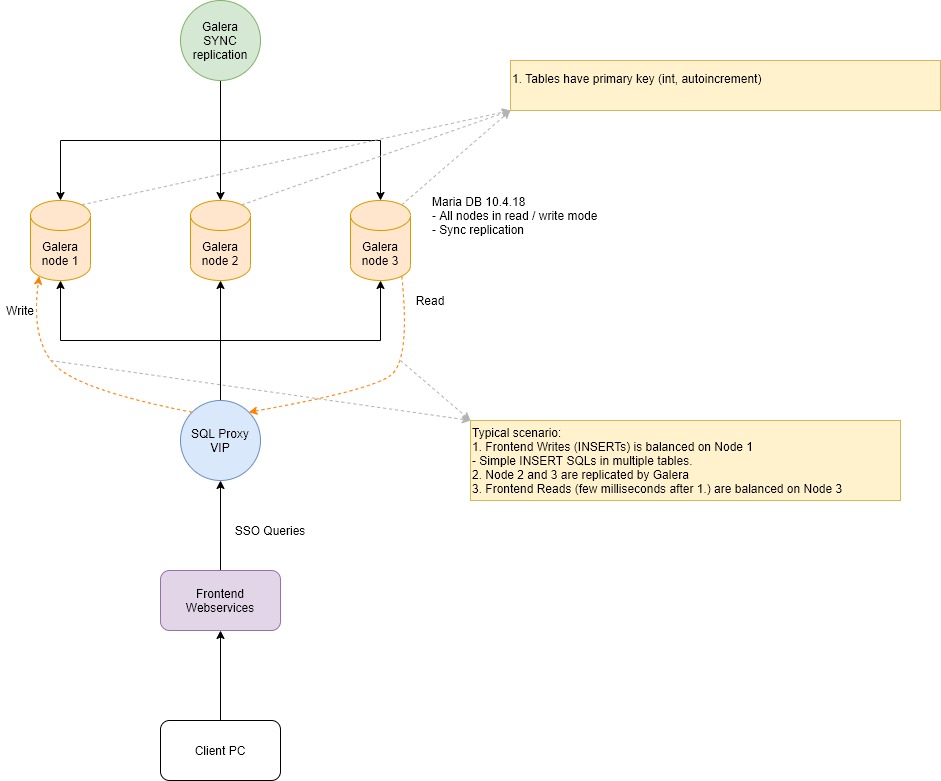
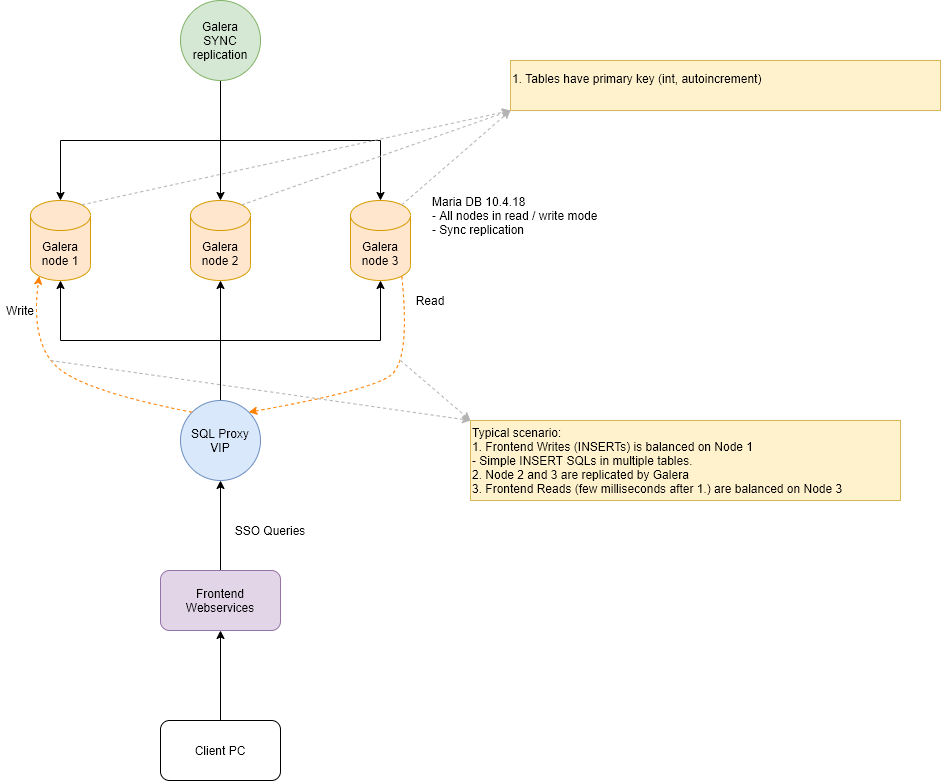
I am attaching the diagram and some specification for your help.
Also, the tables that we are inserting in the first query looks like this one:
CREATE TABLE IF NOT EXISTS `item` (
|
`id` int(11) NOT NULL, |
`name` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT 'Item custom name', |
`external_id` varchar(32) COLLATE utf8_unicode_ci DEFAULT NULL, |
...
|
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
|
|
|
ALTER TABLE `item`
|
ADD PRIMARY KEY (`id`),
|
ADD UNIQUE KEY `external_id` (`external_id`),
|
;
|
|
|
ALTER TABLE `item`
|
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT; |
The SQLs that we are using to insert data looks like:
INSERT INTO `item` SET `name`='Item1', `external_id`='111111', ...; |
The SQLs that reads data are also simple SELECTs.
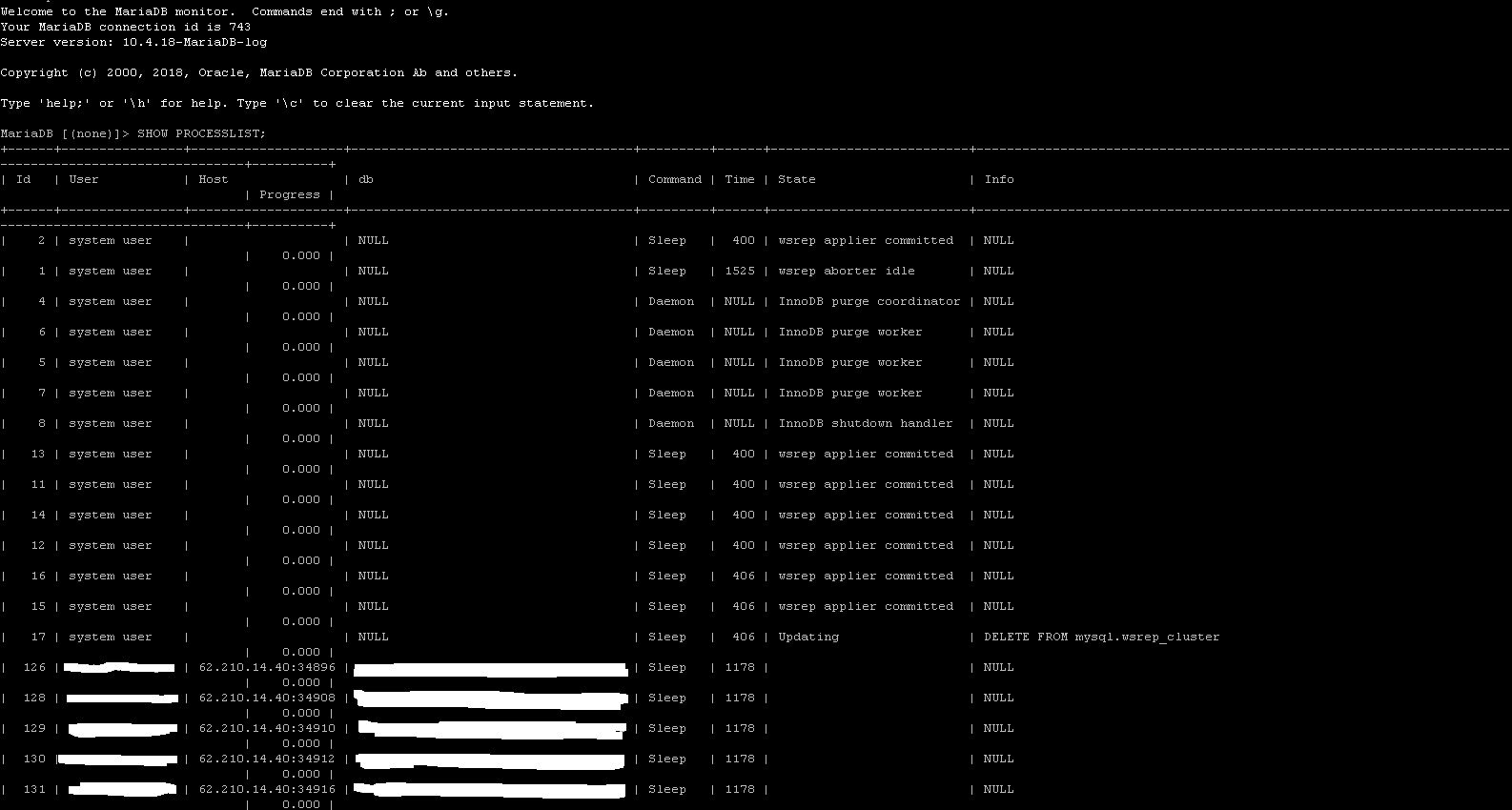
Running "SHOW PROCESSLIST;" on MariaDB hang node looks like (see attached image also 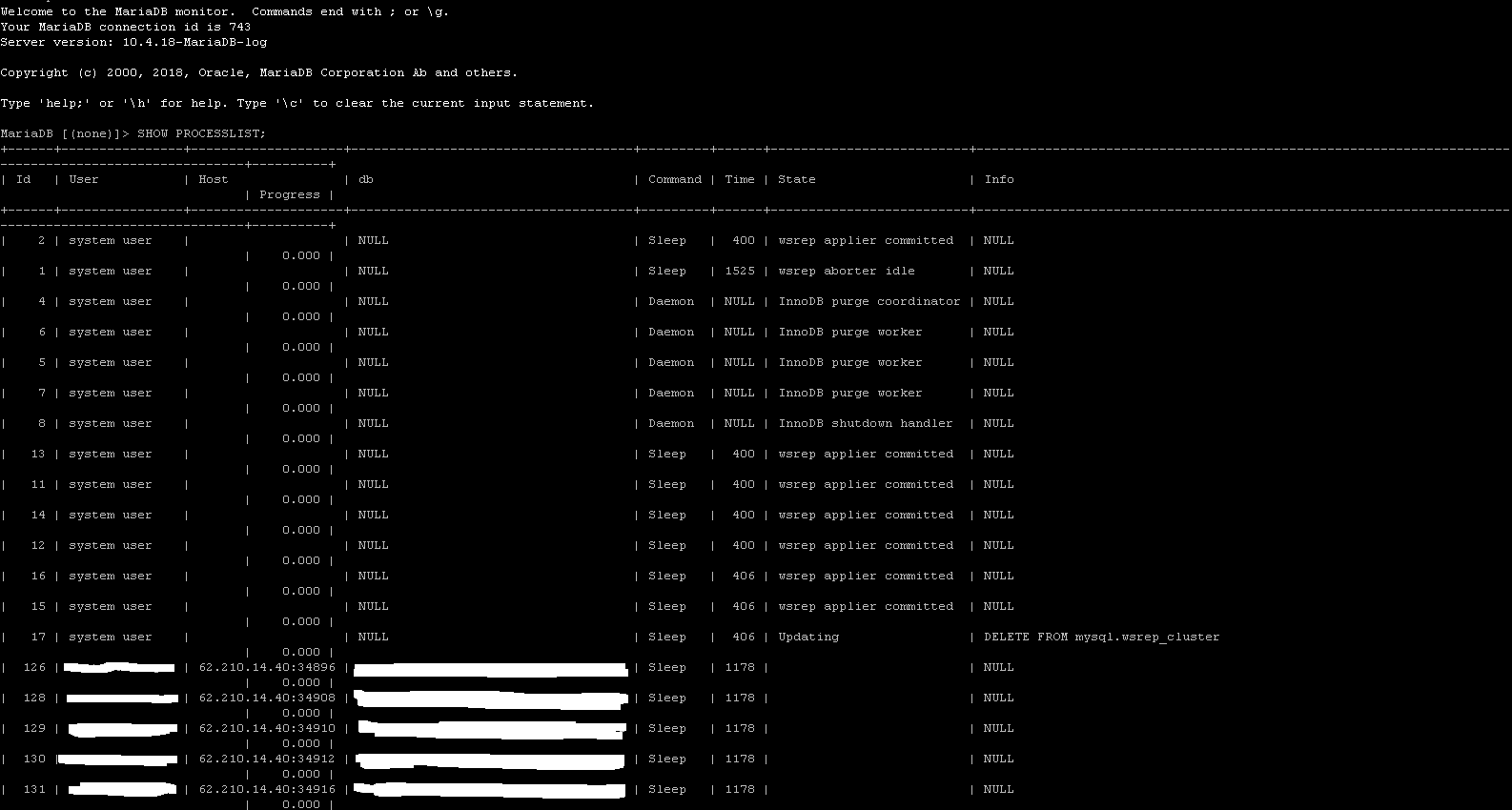 ):
):
|
|
MariaDB [(none)]> SHOW PROCESSLIST;
|
+------+----------------+--------------------+-------------------------------------+---------+------+--------------------------+------------------------------------------------------------------------------------------------------+----------+
|
| Id | User | Host | db | Command | Time | State | Info | Progress |
|
+------+----------------+--------------------+-------------------------------------+---------+------+--------------------------+------------------------------------------------------------------------------------------------------+----------+
|
| 2 | system user | | NULL | Sleep | 400 | wsrep applier committed | NULL | 0.000 | |
| 1 | system user | | NULL | Sleep | 1525 | wsrep aborter idle | NULL | 0.000 | |
| 4 | system user | | NULL | Daemon | NULL | InnoDB purge coordinator | NULL | 0.000 | |
| 6 | system user | | NULL | Daemon | NULL | InnoDB purge worker | NULL | 0.000 | |
| 5 | system user | | NULL | Daemon | NULL | InnoDB purge worker | NULL | 0.000 | |
| 7 | system user | | NULL | Daemon | NULL | InnoDB purge worker | NULL | 0.000 | |
| 8 | system user | | NULL | Daemon | NULL | InnoDB shutdown handler | NULL | 0.000 | |
| 13 | system user | | NULL | Sleep | 400 | wsrep applier committed | NULL | 0.000 | |
| 11 | system user | | NULL | Sleep | 400 | wsrep applier committed | NULL | 0.000 | |
| 14 | system user | | NULL | Sleep | 400 | wsrep applier committed | NULL | 0.000 | |
| 12 | system user | | NULL | Sleep | 400 | wsrep applier committed | NULL | 0.000 | |
| 16 | system user | | NULL | Sleep | 406 | wsrep applier committed | NULL | 0.000 | |
| 15 | system user | | NULL | Sleep | 406 | wsrep applier committed | NULL | 0.000 | |
| 17 | system user | | NULL | Sleep | 406 | Updating | DELETE FROM mysql.wsrep_cluster | 0.000 | |
|
MariaDB / Galera error log shows nothing. We just observed the following difference when the node hangs:
- Instead of having something like (see attached file Galera Log - ETH-UP-Down-OK.txt
 ,for more information):
,for more information):
2021-06-11 14:00:38 14 [Note] WSREP: SQL: 31 DELETE FROM mysql.wsrep_cluster thd: 14 |
2021-06-11 14:00:38 14 [Note] WSREP: SQL: 39 DELETE FROM mysql.wsrep_cluster_members thd: 14 |
- we have something like this (see attached file Galera Log - ETH-UP-Down-FAIL.txt ,for more information):
2021-06-11 14:18:27 2 [Note] WSREP: SQL: 31 DELETE FROM mysql.wsrep_cluster thd: 2 |
Attaching also the server configuration. Maybe it helps. MariaDB-server.cnf![]()
Still could not reproduce the issue with given configuration file. I used following scripts to initiate read/write load
Node1
#!/bin/bash
|
|
|
while true
|
do
|
ITEM_NAME=$(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 30 | head -n 1)
|
ITEM_EX_ID=$(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 30 | head -n 1)
|
for i in `seq 1 20`; do
|
sudo mysql test -e"INSERT INTO item SET name='${ITEM_NAME}${i}', external_id='${ITEM_EX_ID}${i}'" &
|
done
|
sleep 1;
|
done
|
Node3
#!/bin/bash
|
|
|
while true
|
do
|
for i in `seq 1 20`; do
|
sudo mysql test -e"SELECT * FROM item ORDER BY RAND() LIMIT 1;" >/dev/null &
|
done
|
sleep 1;
|
done
|
2021-06-14 4:47:06 15 [Note] WSREP: SQL: 31 DELETE FROM mysql.wsrep_cluster thd: 15
|
2021-06-14 4:47:07 15 [Note] WSREP: SQL: 39 DELETE FROM mysql.wsrep_cluster_members thd: 15
|
2021-06-14 4:47:21 15 [Note] WSREP: SQL: 31 DELETE FROM mysql.wsrep_cluster thd: 15
|
2021-06-14 4:47:21 15 [Note] WSREP: SQL: 39 DELETE FROM mysql.wsrep_cluster_members thd: 15
|
2021-06-14 4:48:41 2 [Note] WSREP: SQL: 31 DELETE FROM mysql.wsrep_cluster thd: 2
|
2021-06-14 4:48:41 2 [Note] WSREP: SQL: 39 DELETE FROM mysql.wsrep_cluster_members thd: 2
|
2021-06-14 4:48:46 2 [Note] WSREP: SQL: 31 DELETE FROM mysql.wsrep_cluster thd: 2
|
2021-06-14 4:48:46 2 [Note] WSREP: SQL: 39 DELETE FROM mysql.wsrep_cluster_members thd: 2
|
Hi,
Thanks a lot for the investigation.
I think your test is slightly different than ours.
As you can observe from the diagram, we have a 4th machine which:
- Is generating some information for node 1
- Is inserting the information in node 1
- Is trying to read SAME information from node 2
In order to facilitate the tests we will try to provide in the next days a script that can replicate this.
Side information: seems that with the latest configuration provided above the issue happens at 50 - 55 ifdown / ifup tries (not at 6-7 as it happened before).
| Attachment | galera-stability.php [ 58157 ] | |
| Attachment | galera-stability.sql [ 58158 ] | |
| Attachment | threads-tool.php [ 58159 ] |
Hi,
As promised, I'm coming back with a solution that can replicate the issue.
The configuration is the following:
1. ProxySQL 2.1.1 (see MariaDB validation diagram.png in the attach)
- standard installation
- custom configuration to avoid bug
MDEV-23328which seems not properly fixed in 10.4.18.- mysql-kill_backend_connection_when_disconnect: false
2. MariaDB 10.4.18 with the configuration provided above
Issue replication
1. Create the database using the galera-stability.sql![]() script provided in attach
script provided in attach
2. Copy the 2 php files (galera-stability.php![]() and threads-tool.php
and threads-tool.php![]() ) provided in attach in /galera-test/ folder under apache root
) provided in attach in /galera-test/ folder under apache root
- the galera-stability.php must be available at the following URL for the threads-tool.php to be able to work correctly:
http://127.0.0.1/galera-test/galera-stability.php
- please configure ProxySQL endopint in galera-stability.php
3. Start a first terminal with:
# php /path/to/galera-test/threads-tool.php |
- this will start bulks of 10 paralel calls to the frontend webservice in a loop:
http://127.0.0.1/galera-test/galera-stability.php
4. Start a second terminal with ifdownupmain.sh script provided above
# /path/to/ifdownupmain.sh |
5. Wait about 10 - 20 network down/up's
6. Galera cluster should start refuse connections
7. Following lines should be visible in galera log:
2021-06-29 15:40:36 157 [Note] WSREP: assigned new next trx id: 36122 |
2021-06-29 15:40:36 174 [Note] WSREP: assigned new next trx id: 36123 |
2021-06-29 15:40:36 174 [Note] WSREP: wsrep_sync_wait: thd->variables.wsrep_sync_wait= 3, mask= 1, thd->variables.wsrep_on= 1
|
2021-06-29 15:40:39 159 [Note] WSREP: wsrep_commit_empty(159)
|
2021-06-29 15:40:39 159 [Note] WSREP: dispatch_command leave
|
thd: 159 thd_ptr: 0x7f66e8036c88 client_mode: local client_state: result trx_state: aborted |
next_trx_id: 36080 trx_id: -1 seqno: -1
|
is_streaming: 0 fragments: 0
|
sql_errno: 1205 message: Lock wait timeout exceeded; try restarting transaction
|
command: 0 query: SELECT (SELECT VARIABLE_VALUE FROM INFORMATION_SCHEMA.GLOBAL_STATUS WHER |
2021-06-29 15:40:39 159 [Note] WSREP: assigned new next trx id: 36124 |
8. Following query should be visible in mariadb.
- Please pay attention to the DELETE FROM mysql.wsrep_cluster SQL and his time.
- Please note that the SQLs following it have greater times and seems they are waiting for this one to finish, but it never does.
MariaDB [(none)]> show full processlist\G;
|
*************************** 1. row ***************************
|
Id: 2
|
User: system user
|
Host:
|
db: NULL
|
Command: Sleep
|
Time: 348
|
State: wsrep applier committed
|
Info: NULL
|
Progress: 0.000
|
*************************** 2. row ***************************
|
Id: 1
|
User: system user
|
Host:
|
db: NULL
|
Command: Sleep
|
Time: 781
|
State: wsrep aborter idle
|
Info: NULL
|
Progress: 0.000
|
*************************** 3. row ***************************
|
Id: 5
|
User: system user
|
Host:
|
db: NULL
|
Command: Daemon
|
Time: NULL
|
State: InnoDB purge worker
|
Info: NULL
|
Progress: 0.000
|
*************************** 4. row ***************************
|
Id: 4
|
User: system user
|
Host:
|
db: NULL
|
Command: Daemon
|
Time: NULL
|
State: InnoDB purge coordinator
|
Info: NULL
|
Progress: 0.000
|
*************************** 5. row ***************************
|
Id: 6
|
User: system user
|
Host:
|
db: NULL
|
Command: Daemon
|
Time: NULL
|
State: InnoDB purge worker
|
Info: NULL
|
Progress: 0.000
|
*************************** 6. row ***************************
|
Id: 7
|
User: system user
|
Host:
|
db: NULL
|
Command: Daemon
|
Time: NULL
|
State: InnoDB purge worker
|
Info: NULL
|
Progress: 0.000
|
*************************** 7. row ***************************
|
Id: 8
|
User: system user
|
Host:
|
db: NULL
|
Command: Daemon
|
Time: NULL
|
State: InnoDB shutdown handler |
Info: NULL
|
Progress: 0.000
|
*************************** 8. row ***************************
|
Id: 11
|
User: system user
|
Host:
|
db: NULL
|
Command: Sleep
|
Time: 348
|
State: wsrep applier committed
|
Info: NULL
|
Progress: 0.000
|
*************************** 9. row ***************************
|
Id: 12
|
User: system user
|
Host:
|
db: NULL
|
Command: Sleep
|
Time: 348
|
State: wsrep applier committed
|
Info: NULL
|
Progress: 0.000
|
*************************** 10. row ***************************
|
Id: 13
|
User: system user
|
Host:
|
db: NULL
|
Command: Sleep
|
Time: 348
|
State: wsrep applier committed
|
Info: NULL
|
Progress: 0.000
|
*************************** 11. row ***************************
|
Id: 14
|
User: system user
|
Host:
|
db: NULL
|
Command: Sleep
|
Time: 348
|
State: wsrep applier committed
|
Info: NULL
|
Progress: 0.000
|
*************************** 12. row ***************************
|
Id: 15
|
User: system user
|
Host:
|
db: NULL
|
Command: Sleep
|
Time: 348
|
State: wsrep applier committed
|
Info: NULL
|
Progress: 0.000
|
*************************** 13. row ***************************
|
Id: 16
|
User: system user
|
Host:
|
db: NULL
|
Command: Sleep
|
Time: 348
|
State: wsrep applier committed
|
Info: NULL
|
Progress: 0.000
|
*************************** 14. row ***************************
|
Id: 17
|
User: system user
|
Host:
|
db: NULL
|
Command: Sleep
|
Time: 348
|
State: Updating
|
Info: DELETE FROM mysql.wsrep_cluster
|
Progress: 0.000
|
*************************** 15. row ***************************
|
Id: 46
|
User: root
|
Host: 62.210.14.36:51522
|
db: stability_test
|
Command: Query
|
Time: 347
|
State: Commit
|
Info: INSERT INTO `item` (
|
`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `field5`, `field6`, `field7`, `field8`, `field9`, `field10` |
) VALUES (
|
NULL, '3i0AZ4GfPSNaeQH6tTIDGfhbS7SIr27m', '3i0AZ4GfPSNaeQH6tTIDGfhbS7SIr27m', 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL |
)
|
Progress: 0.000
|
*************************** 16. row ***************************
|
Id: 47
|
User: root
|
Host: 62.210.14.36:51524
|
db: stability_test
|
Command: Query
|
Time: 347
|
State: Commit
|
Info: INSERT INTO `item` (
|
`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `field5`, `field6`, `field7`, `field8`, `field9`, `field10` |
) VALUES (
|
NULL, '5gezE5Fcd8AH5MNpcI15VJ0eb300Egbb', '5gezE5Fcd8AH5MNpcI15VJ0eb300Egbb', 0, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL |
)
|
Progress: 0.000
|
Hope this brings more clarity and easiness in replicate.
| Attachment | MariaDB valication diagram.png [ 58030 ] |
| Attachment | MariaDB validation diagram.png [ 58160 ] |
{kind=link}
ionut.andras Thank you for the test case. I am able to reproduce the issue with given testcase
MariaDB [stability_test]> show processlist;
|
+-----+-------------+----------------------+----------------+---------+------+--------------------------+------------------------------------------------------------------------------------------------------+----------+
|
| Id | User | Host | db | Command | Time | State | Info | Progress |
|
+-----+-------------+----------------------+----------------+---------+------+--------------------------+------------------------------------------------------------------------------------------------------+----------+
|
| 2 | system user | | NULL | Sleep | 2230 | wsrep aborter idle | NULL | 0.000 |
|
| 1 | system user | | NULL | Sleep | 2230 | Closing tables | NULL | 0.000 |
|
| 4 | system user | | NULL | Daemon | NULL | InnoDB purge worker | NULL | 0.000 |
|
| 3 | system user | | NULL | Daemon | NULL | InnoDB purge coordinator | NULL | 0.000 |
|
| 5 | system user | | NULL | Daemon | NULL | InnoDB purge worker | NULL | 0.000 |
|
| 6 | system user | | NULL | Daemon | NULL | InnoDB purge worker | NULL | 0.000 |
|
| 7 | system user | | NULL | Daemon | NULL | InnoDB shutdown handler | NULL | 0.000 |
|
| 11 | system user | | NULL | Sleep | 2229 | wsrep applier idle | NULL | 0.000 |
|
| 12 | system user | | NULL | Sleep | 2229 | wsrep applier idle | NULL | 0.000 |
|
| 13 | system user | | NULL | Sleep | 2229 | wsrep applier idle | NULL | 0.000 |
|
| 15 | system user | | NULL | Sleep | 2229 | Closing tables | NULL | 0.000 |
|
| 16 | system user | | NULL | Sleep | 2229 | Updating | DELETE FROM mysql.wsrep_cluster | 0.000 |
|
| 17 | system user | | NULL | Sleep | 2229 | wsrep applier idle | NULL | 0.000 |
|
| 18 | system user | | NULL | Sleep | 2229 | wsrep applier idle | NULL | 0.000 |
|
| 22 | root | localhost | stability_test | Query | 0 | Init | show processlist | 0.000 |
|
| 29 | app_user | 192.168.100.40:49252 | stability_test | Query | 1860 | Commit | INSERT INTO `item` (`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `f | 0.000 |
|
| 32 | app_user | 192.168.100.40:49258 | stability_test | Query | 1860 | Update | INSERT INTO `item` (`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `f | 0.000 |
|
| 34 | app_user | 192.168.100.40:49262 | stability_test | Query | 1860 | Commit | INSERT INTO `item` (`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `f | 0.000 |
|
| 38 | app_user | 192.168.100.40:49654 | stability_test | Query | 1860 | Commit | INSERT INTO `item` (`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `f | 0.000 |
|
| 39 | app_user | 192.168.100.40:49656 | stability_test | Query | 1860 | Commit | INSERT INTO `item` (`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `f | 0.000 |
|
| 36 | app_user | 192.168.100.40:49650 | stability_test | Query | 1860 | Commit | INSERT INTO `item` (`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `f | 0.000 |
|
| 40 | app_user | 192.168.100.40:50450 | stability_test | Query | 1860 | Update | INSERT INTO `item` (`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `f | 0.000 |
|
| 42 | app_user | 192.168.100.40:51606 | stability_test | Query | 1859 | Update | INSERT INTO `item` (`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `f | 0.000 |
|
| 43 | app_user | 192.168.100.40:51608 | stability_test | Query | 1860 | Commit | INSERT INTO `item` (`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `f | 0.000 |
|
| 56 | app_user | 192.168.100.40:54048 | stability_test | Query | 1787 | Update | INSERT INTO `item` (`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `f | 0.000 |
|
| 57 | app_user | 192.168.100.40:54050 | stability_test | Query | 1787 | Update | INSERT INTO `item` (`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `f | 0.000 |
|
| 50 | app_user | 192.168.100.40:54052 | stability_test | Query | 1786 | Update | INSERT INTO `item` (`id`, `name`, `external_id`, `count`, `field1`, `field2`, `field3`, `field4`, `f | 0.000 |
|
| Assignee | Jan Lindström [ jplindst ] |
| Fix Version/s | 10.4 [ 22408 ] |
| Status | Open [ 1 ] | Confirmed [ 10101 ] |
ionut.andras One of the screenshot attachments has public space IP address in it. Do you want us to remove that?
Hi Roel,
It is fine. They are VPN closed and temporary test IPs.
Thanks for the remark.
| Priority | Major [ 3 ] | Critical [ 2 ] |
| Assignee | Jan Lindström [ jplindst ] | Mario Karuza [ mkaruza ] |
| Status | Confirmed [ 10101 ] | In Progress [ 3 ] |
| Assignee | Mario Karuza [ mkaruza ] | Jan Lindström [ jplindst ] |
| Status | In Progress [ 3 ] | In Review [ 10002 ] |
| issue.field.resolutiondate | 2021-09-30 10:58:57.0 | 2021-09-30 10:58:57.003 |
| Fix Version/s | 10.4.22 [ 26031 ] | |
| Fix Version/s | 10.5.13 [ 26026 ] | |
| Fix Version/s | 10.6.5 [ 26034 ] | |
| Fix Version/s | 10.4 [ 22408 ] | |
| Resolution | Fixed [ 1 ] | |
| Status | In Review [ 10002 ] | Closed [ 6 ] |
MDEV-23379 deprecated and ignored the setting innodb_thread_concurrency in MariaDB Server 10.5.5. I adjusted the "fix version" accordingly. The MariaDB Server 10.6 series was never affected by this.
| Link |
This issue relates to |
| Fix Version/s | 10.5.5 [ 24423 ] | |
| Fix Version/s | 10.5.13 [ 26026 ] | |
| Fix Version/s | 10.6.5 [ 26034 ] |
Hi Marko,
In conclusion, setting this variable: innodb_thread_concurrency=0, should improve things?
Thanks in advance.
ionut.andras, with regard to MDEV-23379, I did not test earlier release series than 10.5 at extreme load. It might be that already 10.3 significantly improved scalability thanks to reducing contention on trx_sys.mutex. 10.5 introduced further changes, to reduce contention on buf_pool.mutex and fil_system.mutex.
| Link |
This issue duplicates |
| Fix Version/s | 10.5.13 [ 26026 ] | |
| Fix Version/s | 10.5.5 [ 24423 ] |
| Workflow | MariaDB v3 [ 122552 ] | MariaDB v4 [ 159379 ] |
Could not reproduce the issue using the given IP up/down script. I have used sysbench to simulate the load on all nodes. It will be great if you could provide more details about the queries which are executing on cluster nodes.