Details
-
Task
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
Description
I would like to suggest the possibility of developing a ZIP Type CONNECT Storage Engine, which could work directly with ZIP files (which contain CSV or XML into them) without the need of previously decompressing such files and importing them into the database.
Thank you. Hope my suggestion is useful.
Kind regards,
Juan Telleria
Attachments
Issue Links
- relates to
-
MDEV-12354 MariaDB CONNECT CSV (Zipped Tables)
-

- Closed
-
Activity
| Field | Original Value | New Value |
|---|---|---|
| Assignee | Olivier Bertrand [ bertrandop ] |
Thank you Oliver.
What I am looking forward to do is the following:
- I have one folder which contain several .zip files which contain .csv (With the same structure) into each of them.
- I would like to point to that folder using FILE_NAME *.zip and treat such files as a whole, sharing the same table structure.
Thank you.
| Status | Open [ 1 ] | In Progress [ 3 ] |
I have developed a first implementation of this that I pushed and will be distributed in the next versions of MariaDB.
Because it is not fully tested and with important limitations, it will not be documented yet. However, to enable your testing it, here is how to use it:
Let's suppose you have a CSV file from which you would create a table by:
create table emp
|
... optional column definition
|
engine=connect table_type=CSV file_name='E:/Data/employee.csv'
|
sep_char=';' header=1;
|
Now if the CSV file is included in a ZIP file, the CREATE TABLE becomes:
create table empzip
|
... optional column definition
|
engine=connect table_type=CSV file_name='employee.zip'
|
sep_char=';' header=1 zipped=1 option_list='Entry=emp.csv';
|
The file_name option is the name of the zip file. The entry option is the name of the entry inside the zip file. If there is only one entry file inside the zip file, this option can be omitted.
If the table is made from several files such as emp01.csv, emp02.csv, etc., the standard create table would be:
create table empmul (
|
... required column definition
|
) engine=connect table_type=CSV file_name='E:/Data/emp*.csv'
|
sep_char=';' header=1 multiple=1;
|
But if these files are all zipped inside a unique zip file, it becomes:
create table empzmul
|
... optional column definition
|
engine=connect table_type=CSV file_name='E:/Data/emp.zip'
|
sep_char=';' header=1
|
option_list='Entry=emp*.csv';
|
Here the entry option is the pattern that the files inside the zip file must match. If all entry files are ok, the entry option can be omitted (meaning all entry files)
If the table is created on several zip files, it is specified as for all other multiple tables:
create table zempmul (
|
... required column definition
|
) engine=connect table_type=CSV file_name='E:/Data/emp*.zip'
|
sep_char=';' header=1 multiple=1 option_list='Entry=employee.csv';
|
Here again the entry option is used to restrict the entry file(s) to be used inside the zip files and can be omitted if all are Ok.
Catalog table can be created by adding catfunc=columns.
This first implementation have many restrictions:
- This is a read only implementation. No insert, update or delete.
- The inside files are decompressed into memory. Memory problems may arise with huge files.
- Only file types that can be handled from memory are eligible for this. This includes DOS, FIX, BIN, CSV, FMT, JSON but XML is not yet eligible.
- No optimization such as partitioning, indexing or block indexing.
A ZIP table type is also available. It is not meant to read the inside files but to display information about the zip file contain. For instance:
create table xzipinfo2 (
|
fn varchar(256)not null,
|
cmpsize bigint not null flag=1,
|
uncsize bigint not null flag=2,
|
method int not null flag=3)
|
engine=connect table_type=ZIP file_name='E:/Data/Json/cities.zip';
|
This will display the file name, compressed size, uncompressed size and compress method of all files inside the zip file.
| Attachment | Data Structure.png [ 43001 ] |
{kind=link}
Wow! Thank you Oliver! Great Job! :-D
I will try it at home as soon as possible.
This is how my production data looks like:
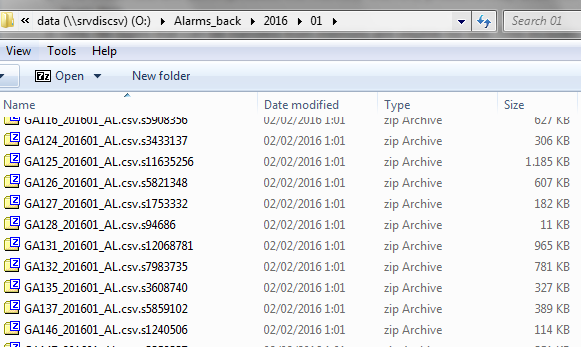
I have several Zip files, and each file contains 1 CSV with the same name than the Zip file. All of the CSV contained into ZIP files contain the same data structure.
What I will try to do is something as follows:
{{create table empzip
... optional column definition
engine=connect table_type=CSV file_name='*.csv'
sep_char=';' header=1
option_list='Zipfile=E:/Data/*.zip';}}
And treat all CSV in the folder as a hole.
It also would be useful to be able to chose between MEMORY or ARIA (MYISAM) data allocation.
For me reading capabilities are enough.
Hmmm... this will not work. Firstly you forgot to specify "multiple=1". But what I did, when multiple is specified for table implying ZIP is not to look for multiple zip files but to look for multiple entries in one zip files. I mean that it would work if all your CSV files where zipped together in the same zip file. Now I realize that I must make the difference between these different use of the multiple option.
In your case, what you can do is to create a table for each zipped CSV file and, to use them as a whole, to create a TBL table on all of them.
About an alternative to MEMORY, this could be FILE or PIPE but not another engine format. If you want to have an ARIA table, you should do:
CREATE TABLE xxx ENGINE=ARIA as SELECT * FROM connect-zip-table.
|
Yep,
I totally agree on how to save data in an ARIA ENGINE table.
As regards multiple option, I would suggest that this variable supports 2 alternatives:
- Multiple (N) CSV files in 1 ZIP: multiple=1
- Or 1 CSV file in multiple (N) ZIP: multiple=2
I am working on this. The big change is that now the file_name option will be the name of the zip file(s). So multiple will work as before and will be used to work on several zip files. (note that multiple=2 already exists with a different meaning)
Inside the zip file(s) the entry option (in option_list) is used to tell which entry files to use:
- With no wildcard it tells which internal file to use.
- If entry contains wildcard characters, all entries verifying the pattern are used (no need for multiple)
- If entry is not specified, all internal files are used.
Doing so, your table can be created by:
create table empzip (
|
... required column definition
|
) engine=connect table_type=CSV file_name='E:/Data/*.csv'
|
sep_char=';' header=1 multiple=1;
|
No need for entry as your zip files only contain one file.
Note: this is not pushed yet. I hope I can do it before new MariaDB versions are released.
Thank you! ![]()
Hope this development is also useful to other people.
Kind regards,
Juan
This new version is now documented.
Also some restrictions have been released:
- XML is now supported.
- Column definition discovery is available for table types supporting it.
- Indexing and block indexing is supported.
- Partitioning is supported.
| issue.field.resolutiondate | 2016-12-26 11:41:18.0 | 2016-12-26 11:41:18.899 |
| Fix Version/s | 10.0.29 [ 22312 ] | |
| Fix Version/s | 10.1.21 [ 22113 ] | |
| Fix Version/s | 10.2.4 [ 22116 ] | |
| Resolution | Fixed [ 1 ] | |
| Status | In Progress [ 3 ] | Closed [ 6 ] |
Hi Oliver!
One little question:
You told me that all CSV files contained into the ZIP files are decompressed in-memory. Therefore, ¿Would it be possible to establish a variable to decompress them into Disk?
It is slower, but these would aboid Memory Problems to arise.
My mayor concern is the following:
When I create a Table such as the following, to many files are saved into Memory, causing the computer to crash:
create table zempmul (
|
... required column definition
|
) engine=connect table_type=CSV file_name='E:/Data/emp*.zip' |
sep_char=';' header=1 multiple=1 zipped=yes |
option_list='Entry=employee.csv'; |
Maybe one solution would be an optional decompression of files in a 1 by 1 basis.
Thank you.
Kind regards,
Juan Telleria
I don't understand; decompression of files in a 1 by 1 basis is what I do.
Are you sure your crash is due to a memory problem?
How many zipped CSV files have you and how big are they?
I have 590 zipped files (.zip) in my folder, each of them with 20.000 [Rows] aprox.
What I stated It was more a concern than a problem I had had. I was afraid of that happening and conditioning others users of the server with such operation, as I did not fully understood the internal behaviour of the engine for CSV tables at all:
Knowing that decompression is done in a 1 by 1 basis (Although multiple *.zip files are selected) is all I needed to know.
Thank you! ![]()
Juan
- P.D.: Yesterday I also tried the CONNECT ODBC engine for first time and works superb too

I pushed a new version allowing creating zipped tables that will be available in next MariaDB versions. Two ways are available to make the zip file:
Insert method:
insert can be used to make the table file for table types based on records (this excludes XML and JSON when pretty is not 0). However, the current implementation of the used package (minizip) does not support adding to an already existing zip entry. This means that when executing an insert statement the inserted records are not added but replace the existing ones. Therefore, only three ways are available to do so:
- Using only one insert statement to make the table. This is possible only for small tables and is principally useful when making tests.
- Making the table from the data of another table. This can be done by executing an “insert into table select * from another_table” or by specifying “as select * from another_table” in the create table statement.
- Making the table from a file whose format enables to use the “load data infile” statement.
File zipping method:
This method enables to make the zip file from another file when creating the table. It applies to all table types including XML and JSON. It is specified in the CREATE TABLE statement with the LOAD option. For example:
create table XSERVZIP (
|
NUMERO varchar(4) not null,
|
LIEU varchar(15) not null,
|
CHEF varchar(5) not null,
|
FONCTION varchar(12) not null,
|
NOM varchar(21) not null)
|
engine=CONNECT table_type=XML file_name='E:/Xml/perso.zip' zipped=1
|
option_list='entry=services,load=E:/Xml/serv2.xml';
|
When executing this statement, the serv2.xml file will be zipped as perso.zip. The entry name must be specified as well as the column descriptions that cannot be retrieved from the zip file entry that does not exist yet. To add a new entry to an existing zip file, specify 'append=1' in the option list.
It is even possible to create a multi-entries table from several files:
CREATE TABLE znewcities (
|
_id char(5) NOT NULL,
|
city char(16) NOT NULL,
|
lat double(18,6) NOT NULL `FIELD_FORMAT`='loc:[0]',
|
lng double(18,6) NOT NULL `FIELD_FORMAT`='loc:[1]',
|
pop int(6) NOT NULL,
|
state char(2) NOT NULL
|
) ENGINE=CONNECT TABLE_TYPE=JSON FILE_NAME='E:/Json/newcities.zip'
|
ZIPPED=1 LRECL=1000
|
OPTION_LIST='Load=E:/Json/city_*.json,mulentries=YES,pretty=0';
|
Here the files to load are specified with wildcard characters and the MULENTRIES options must be specified. However, the ENTRY option must not be specified, entry names will be made from the file names.
| Attachment | Folder Example.png [ 43316 ] |
{kind=link}
Hi Oliver!
It just occurred to me a little feature for CONNECT Zipped File Table which could be quite cool to implement.
I could really life without it (By developing a procedure), but here it goes in case your are keen on adding a new cool and simple feature ![]() :
:
create table zempmul (
|
... required column definition
|
) engine=connect table_type=CSV file_name='E:/Data/%/*.zip' |
sep_char=';' header=1 multiple=1 zipped=yes |
option_list='Entry=employee.csv'; |
Notice the % symbol in file_name table option. This would enable us to import all the files inside our "Data" Folder and its subfolders which contain *.zip files (And CSV into them).
So if we for example had a folder like mine:
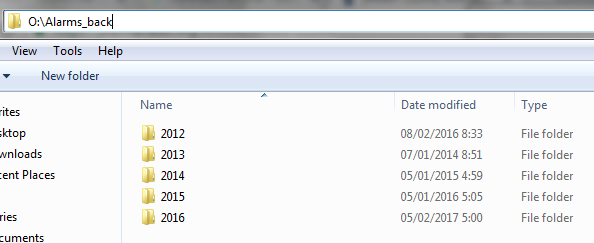
Which contains Alarm Logs in:
- Year Folders.
- Month Folders.
- Day Folders.
All containing ZIP files with CSV into them with the same table structure. I would be able to import all of them into MariaDB (A ColumnStore Engine for Example) into my computer with a really simple query.
If such implementation is complicated I could develope an SQL procedure my own which I could share.
Kind regards,
Juan
This should done with multiple tables provided that:
- Multiple be added a subfolder option.
- Not considering an error for zip files that do not contain the entry.
Added to my TODO list.
| Attachment | Subfolder Option.PNG [ 43394 ] |
{kind=link}
| Comment |
[ Hi!
Could the "subfolder" option be developed please (in case it only takes little work, otherwise no) before MariaDB 10.2.4 RC turns out to be GA. They have changed the data structure in my work from monthly folders to daily folders, and is somehow a chaos :P: !Subfolder Option.PNG|thumbnail! Thank you :-) ] |
| Comment |
[ Some ideas for subfolder option (From Stack Overflow):
[Move all files in subfolders to a parent folder|http://superuser.com/questions/999922/move-all-files-from-multiple-subfolders-into-the-parent-folder] But actually, I would not move the files (nor copy them), because that is time consuming; and I would simply perform in C# the following command: [For /R (CMD)|https://ss64.com/nt/for_r.html] ] |
Done. To include files in sub-folders, specify multiple=3. This is general, not only for zipped files.
Thank you a lot Oliver! :-D
I hope that with this new ZIP CONNECT Engine Type we are able to do MariaDB even better.
Kind regards,
Juan
| Comment |
[ * New sub-folder option (_multiple=3_) Information could be added to Knowledge Base documentation.
* ¿Will it be distributed from MariaDB 10.2.4 RC?. ] |
As I see on CONNECT webpage,this new feature works from MariaDB 10.1.22 on (Connect 1.05.0003).
Thank you! ![]()
| Comment |
[ *ERRORS:*
* Got error 174 'Open() error 13 on C:/Users/ANALISISOTS/Desktop/GA155AL15012017.csv: Permission denied' from CONNECT. * Got error 174 'Zipfile open error on C:/Users/ANALISISOTS/Desktop/GA155AL15012017.zip' from CONNECT. Are due to Directory permission issues on Windows: Same CREATE TABLE for CONNECT CSV (Zipped = 1 | 0) works perfectly on MariaDB 10.1 directory, but it does not work on other Windows paths. This is due to the fact that mysqld can only read MariaDB 10.1 folder. ¿Which would be the easiest way to solve this? Thank you. ] |
When using MULTIPLE=1 for importing 566 CSV Zipped Files, of 1000 rows each one, my Server ShutsDown.
My CREATE TABLE is as follows:
CREATE TABLE dispoin.t_CONNECT_CSV_Zipped_DISPOIN_Server
|
(
|
`SCADA` VARCHAR(25) DEFAULT NULL, |
`TAG` VARCHAR(25) DEFAULT NULL, |
`ID_del_AEG` VARCHAR(25) DEFAULT NULL, |
`Descripcion` VARCHAR(255) DEFAULT NULL, |
`Time_ON` VARCHAR(19) DEFAULT NULL, |
`Time_OFF` VARCHAR(19) DEFAULT NULL, |
`Delta_Time` VARCHAR(19) DEFAULT NULL, |
`Comentario` VARCHAR(255) DEFAULT NULL, |
`Es_Alarma` VARCHAR(5) DEFAULT NULL, |
`Es_Ultima` VARCHAR(5) DEFAULT NULL, |
`Comentarios` VARCHAR(255) DEFAULT NULL |
)
|
ENGINE = CONNECT
|
TABLE_TYPE = CSV
|
FILE_NAME='//srvdiscsv/data/2017-03-23/*AL*.zip' |
HEADER=NO
|
SEP_CHAR=';' |
MULTIPLE=1 |
ZIPPED=YES
|
READONLY=YES
|
OPTION_LIST='maxerr=10000'; |
In the same folder. For 1 single CSV ZIP file, same format (MULTIPLE=NO) works perfect.
I have just uploaded my error LOG.
I will CREATE another issue with the bug.
| Attachment | error log.log [ 43490 ] |
| Link |
This issue relates to |
| Attachment | P700-error.log [ 43493 ] |
Server shutdows for:
CREATE TABLE Table_Name
AS
SELECT
*
FROM
t_CONNECT_Table;
But not for:
SELECT
*
FROM
t_CONNECT_Table;
It only throughs a fatal error.
Also MULTIPLE=3 does not seem to be still available for CONNECT 1.05.0003
With OPTION_LIST='accept=YES' also crashes.
And with:
OPTION_LIST='maxerr=1000000000000000000000000000000000000000,accept=YES' query never ends.
Because you are currently the only user of that new feature,regard it as experimental and not to be used on production server.
I'll see what can cause these errors. Probably an exhausted memory problem.
| Resolution | Fixed [ 1 ] | |
| Status | Closed [ 6 ] | Stalled [ 10000 ] |
I will try with fewer files and let you now.
Till I hit the upper limit.
| Attachment | Test Data.zip [ 43494 ] |
I have been testing the data, and I have both good and bad news. This is how I did my test:
If I put in the same test folder (Based on test data):
- 597 zipped csv files.
- And the same 597 unzipped csv files.
CONNECT CSV MULTIPLE=YES UNZIPPED CSV SAME FOLDER
If I execute the followings queries:
CREATE TABLE dispoin.t_CONNECT_CSV_Zipped_DISPOIN_Server
|
(
|
`SCADA` VARCHAR(4000) DEFAULT NULL, |
`TAG` VARCHAR(4000) DEFAULT NULL, |
`ID_del_AEG` VARCHAR(4000) DEFAULT NULL, |
`Descripcion` VARCHAR(4000) DEFAULT NULL, |
`Time_ON` VARCHAR(4000) DEFAULT NULL, |
`Time_OFF` VARCHAR(4000) DEFAULT NULL, |
`Delta_Time` VARCHAR(4000) DEFAULT NULL, |
`Comentario` VARCHAR(4000) DEFAULT NULL, |
`Es_Alarma` VARCHAR(4000) DEFAULT NULL, |
`Es_Ultima` VARCHAR(4000) DEFAULT NULL, |
`Comentarios` VARCHAR(4000) DEFAULT NULL |
)
|
ENGINE = CONNECT
|
TABLE_TYPE = CSV
|
FILE_NAME='D:/DISPOIN CONNECT CSV test/*AL*.csv' |
HEADER=NO
|
SEP_CHAR=';' |
MULTIPLE=1 |
QUOTED=0 |
ZIPPED=NO
|
READONLY=YES
|
OPTION_LIST='accept=YES'; |
|
|
SELECT
|
*
|
FROM
|
dispoin.t_CONNECT_CSV_Zipped_DISPOIN_Server;
|
OR
CREATE TABLE dispoin.t_CONNECT_CSV_Zipped_DISPOIN_Server
|
(
|
`SCADA` VARCHAR(4000) DEFAULT NULL, |
`TAG` VARCHAR(4000) DEFAULT NULL, |
`ID_del_AEG` VARCHAR(4000) DEFAULT NULL, |
`Descripcion` VARCHAR(4000) DEFAULT NULL, |
`Time_ON` VARCHAR(4000) DEFAULT NULL, |
`Time_OFF` VARCHAR(4000) DEFAULT NULL, |
`Delta_Time` VARCHAR(4000) DEFAULT NULL, |
`Comentario` VARCHAR(4000) DEFAULT NULL, |
`Es_Alarma` VARCHAR(4000) DEFAULT NULL, |
`Es_Ultima` VARCHAR(4000) DEFAULT NULL, |
`Comentarios` VARCHAR(4000) DEFAULT NULL |
)
|
ENGINE = CONNECT
|
TABLE_TYPE = CSV
|
FILE_NAME='D:/DISPOIN CONNECT CSV test/*AL*.csv' |
HEADER=NO
|
SEP_CHAR=';' |
MULTIPLE=1 |
QUOTED=0 |
ZIPPED=NO
|
READONLY=YES
|
OPTION_LIST='maxerr=1000000'; |
|
|
SELECT
|
*
|
FROM
|
dispoin.t_CONNECT_CSV_Zipped_DISPOIN_Server;
|
In both cases query executes sucessfully.
However, this query does never end, but the server does never crash:
CREATE TABLE dispoin.t_CONNECT_CSV_Zipped_DISPOIN_Server
|
(
|
`SCADA` VARCHAR(4000) DEFAULT NULL, |
`TAG` VARCHAR(4000) DEFAULT NULL, |
`ID_del_AEG` VARCHAR(4000) DEFAULT NULL, |
`Descripcion` VARCHAR(4000) DEFAULT NULL, |
`Time_ON` VARCHAR(4000) DEFAULT NULL, |
`Time_OFF` VARCHAR(4000) DEFAULT NULL, |
`Delta_Time` VARCHAR(4000) DEFAULT NULL, |
`Comentario` VARCHAR(4000) DEFAULT NULL, |
`Es_Alarma` VARCHAR(4000) DEFAULT NULL, |
`Es_Ultima` VARCHAR(4000) DEFAULT NULL, |
`Comentarios` VARCHAR(4000) DEFAULT NULL |
)
|
ENGINE = CONNECT
|
TABLE_TYPE = CSV
|
FILE_NAME='D:/DISPOIN CONNECT CSV test/*AL*.csv' |
HEADER=NO
|
SEP_CHAR=';' |
MULTIPLE=1 |
QUOTED=0 |
ZIPPED=NO
|
READONLY=YES;
|
|
|
SELECT
|
*
|
FROM
|
dispoin.t_CONNECT_CSV_Zipped_DISPOIN_Server;
|
So good news! Multiple works perfectly for uncompresed files.
CONNECT CSV MULTIPLE=YES ZIPPED CSV SAME FOLDER
On the other hand, if I use the following query, making use of the zipped CSV files, query fails:
CREATE TABLE dispoin.t_CONNECT_CSV_Zipped_DISPOIN_Server
|
(
|
`SCADA` VARCHAR(4000) DEFAULT NULL, |
`TAG` VARCHAR(4000) DEFAULT NULL, |
`ID_del_AEG` VARCHAR(4000) DEFAULT NULL, |
`Descripcion` VARCHAR(4000) DEFAULT NULL, |
`Time_ON` VARCHAR(4000) DEFAULT NULL, |
`Time_OFF` VARCHAR(4000) DEFAULT NULL, |
`Delta_Time` VARCHAR(4000) DEFAULT NULL, |
`Comentario` VARCHAR(4000) DEFAULT NULL, |
`Es_Alarma` VARCHAR(4000) DEFAULT NULL, |
`Es_Ultima` VARCHAR(4000) DEFAULT NULL, |
`Comentarios` VARCHAR(4000) DEFAULT NULL |
)
|
ENGINE = CONNECT
|
TABLE_TYPE = CSV
|
FILE_NAME='D:/DISPOIN CONNECT CSV test/*AL*.zip' |
HEADER=NO
|
SEP_CHAR=';' |
MULTIPLE=1 |
QUOTED=0 |
ZIPPED=YES
|
READONLY=YES
|
OPTION_LIST='accept=YES'; |
|
|
SELECT
|
*
|
FROM
|
dispoin.t_CONNECT_CSV_Zipped_DISPOIN_Server;
|
Query fails and the server shutdown, showing before some strange characters. So I think the bug is due to some kind on failure on character collation.
As you told me some time ago, zipped files are decompressed in memory one by one, so I don't think it is a memory issue.
Thank you for your help ![]()
Kind regards,
Juan
Another hint:
When trying to import by using multiple 55.409 CSV files in the same folder, I obtained an error saying:
- Got error 122 'Not enough memory in Work area for request of 44040 (used=67108704 free=160)' from CONNECT.
The biggest CSV file I tried to import had 31.000 KB; and all the CSV files consisted in a total size sum of 10 [GB].
It's all about CONNECT CSV Engine heavy using.
This is why I am suspecting a memory problem.
Now there is an easy turnaround. The size of the memory used by CONNECT can be specified in the connect_work_size variable and is 64M by default. This is relatively small for most modern computers and you can easily specify a much greater value depending on your physical memory.
Note: If you change it after the server was started, specify a numerical value (K, M, or G are not accepted)
I have set connect_work_size to the maximum allowed, 4 [GB], and I will give it a try.
However, some solutions to the bug could be:
- When not enough connect_work_size memory, CONNECT could throw an error code, instead of shutting down the hole server.
- In case it was a memory problem, use disk when connect_work_size memory is exceeded, and throw a warning.
The best is to try test data. Thank you! ![]()
4GB will fail unlike you have a machine with more than 4G available for programs!
Setting connect_work_size to 4GB actualy worked for me! Thank you a lot! ![]()
![]()
![]()
For both zipped and Unzipped files using multiple.
It am using Windows x64 bits. However, I think that setting connect_work_size to 512 MB might be enough.
However:
- CONNECT shall trigger a warning or error when this happens, and not making crash the hole server.
- ¿CREATE TABLE t_Table_Name AS SELECT * FROM t_CONNECT_CSV_Zipped_File_Table would properly work? ¿Or the Server would also crash?
- Would it be possible to set connect_work_size to more than 4 [GB] with MariaDB x64.
Thank you! :-D :-D
¿I also would like to test CONNECT Multiple=3 at home and see how it works, is it distributed with MariaDB 10.2.4 RC?
Thank you :-D
As you told me that files are decompressed 1 by 1, I suppose that setting 4GB connect_work_size is the upper limit for single CSV and Zipped File Tables to be decompressed in memory.
Hmmm... testing all this in Debug mode, I have seen that the 400 first tables are correctly processed, then an error occurs explaining why your server stopped but at this point I don't see memory problems. Trying to correct that bug, I found that something is looping explaining your queries that never ended.
All this will take me some time to really find what's wrong.
It is ok.
I thought that by increasing connect_work_size problem was already solved.
Thank you a lot :-D :-D :-D
I cannot understand why increasing the memory can have solved your problem because I found the cause of it and it is not a memory problem at all.
What happened is that some of your zip files, for example W0542AL20112016.CSV.zip, have no line feed ending their last record and this raises an exception causing the server to crash. This is a bug that I fixed.
Another problem, requiring to specify accept= YES is that the W0782AL20112016.zip file has date specified in 12 hours (with AM PM) causing an error because the date fields, specified with a length of 19 are too small.
There is also the fact that the query never ends when specifying Maxerr=100 but it is not related to multiple and occurs as well when working only on this file.
Thank you :-D
When I tested it before leaving work what solved my problem was both increasing the memory, and specifying accept=YES; after what I was able to upload all files successfully.
Maybe one solution could be that, when Multiple=1 founds a file wrongly formated, ¿It excludes it and raises a Warning indicating file error?
What really worried me was the server crash, but as long it is fixed, brilliant work :-D
Also I was really impressed of how fast CONNECT CSV Engine Uploaded the CSVs ![]()
Indeed, accept=YES masks the length error (you should have a lot of warnings telling this)
However, the other error, which is not fixed in your version, should make your server to crash as long as you work with files such as W0542AL20112016.CSV.zip. This is due to a buffer overflow and perhaps by chance increasing the memory also made this bug not fatal.
If you make a table on just that file, it should crash and, if not, you'll see that the last record has been truncated by one byte.
But the bug is still there and I guess you will have more problems. Again: continue testing but don't use it in production applications.
If you attach here the last version of ha_connect plugin I can test it on Monday and give you feedback.
On the other hand, I think that when using multiple=1 or multiple=3; wrong files shall be excluded, and drop a warning.
Thank you a lot!
Juan
Or maybe, better, there could be at option_list an option which allows such behaviour ![]()
I was thinking... My suggestion is not good, maybe the best would be to allow a behaviour such as maxerr=MAXVALUE, which internally discards failures either at row level or at file level.
OB: This is what Maxerr does at row level. Accept=YES is a way to accept all errors. In the case of field too small, the value is just truncated. Of course, in this case the real fix is to increase the column length.
However, during next week I can do at work any test necessary in order to assure that CONNECT CSV can be used with 100% confidence under heavy stress conditions: lots of files, etc.
| Attachment | connect.zip [ 43504 ] |
I attached the source of the last version of connect (undistributed yet) as a zip file connect.zip.
Made by:
create table zconn (line varchar(1024)) engine=connect table_type=DOS zipped=1
|
file_name='C:/Ber/Doc/connect.zip'
|
option_list='Load=C:/MariaDB-10.1/MariaDB/storage/connect/*.*,Mulentries=YES';
|
In 0.30 sec.
Because specified as *.* it contains a few files that do not belong to the source.
TEST
I tried to do some test on the new code CONNECT CSV for Zipped Tables in MariaDB 10.2.4 (ZIP Download), and see how it works, in order to give you some feedback, but I did not manage to compile it for test.
However, as soon as it is released, I'll give you some feedbak on it, about how CONNECT CSV with Multiple=1 and Multiple=3 works; along with maxerr and accept in option_list.
However, I did study C++ during my university career (Now I have it a little bit forgotten), and as I can see, zipped file table code is written with a great level of accuracy.
KNOWLEDGE BASE DOCUMENTATION
On the other hand, I would suggest that "multiple" table option use is also explained in Knowledge Base in:
OB: multiple applies to all file table types, not only to CSV. This is why it is documented in the general file table part.
I attach here some hand-made documentation I made for myself, in case someone wants to complete Knowledge Base CONNECT CSV Documentation.
Thank you ![]()
Kind regards,
Juan
| Attachment | CONNECT CSV Table Type.pdf [ 43508 ] |
Actually, in version Connect 1.05.0003, I was not able to use yet Multiple=3.
Really looking forward towards this new feature ![]()
| Resolution | Fixed [ 1 ] | |
| Status | Stalled [ 10000 ] | Closed [ 6 ] |
| Summary | SUGGESTION: CONNECT Storage Engine - ZIP Engine | CONNECT Storage Engine - ZIP Engine |
It did not fail, I simply did not know how to do it (My fault).
I'll try it again: downloading mariadb-10.2.4.tar.gz and connect.zip
As soon as it is available in the official development release I will test it.
Thank you ![]()
No couldn't, sorry, as soon as it is available "ha_connect" plug-in I'll test it however and give feedback ![]()
Just discovered how to "Edit" Knowledge Base Documentation.
As soon as I can I will improve the one of "CONNECT - Zipped File Tables" ![]() .
.
The coordinator in charge of the CONNECT knowledge base documentation is Ian Gilfillan (ian@mariadb.org![]() )
)
Please contact him if you want to update the documentation.
Thanks.
Just made little changes in Knowledge Base Documentation for CONNECT Zipped File Tables:
I wrote to Ian Gilfillan last Friday giving him notice of such notifications as you requested me.
Hope this helps to make CONNECT CSV for Zipped Type Tables more widely available to everyone.
Kind regards,
Juan
| Workflow | MariaDB v3 [ 78319 ] | MariaDB v4 [ 133001 ] |
I shall see what I can do. I seems that zlib's minizip can be used to implement this but it is not so simple.
Sorry I cannot give a high priority to this. Be patient.