Details
-
Bug
-
Status: Closed (View Workflow)
-
 Minor
Minor
-
Resolution: Fixed
-
10.5.8
-
ARMv8
Description
From the latest Mysql 8.0.23(2021/1/18) release, we found there are the same optimization towards MY_RELAX_CPU. See below
https://github.com/mysql/mysql-server/commit/f2a4ed5b65a6c03ee1bea60b8c3bb4db64dbed10
In current situation for Mariadb server, we introduced
define UT_RELAX_CPU() _asm_ _volatile_ ("":::"memory")
like https://jira.mariadb.org/browse/MDEV-23633 .
For the specific instruction, such as DMB/DSB/ISB(https://developer.arm.com/documentation/dui0489/c/CIHGHHIE), we need to deep analysis or test on ARM, which one is good for ARM.
So this JIRA ticket will trace the test result and following fix/upgrade for this goal. But let's wait for whether this extra operation is visible in some benchmarks.
Attachments
Issue Links
- causes
-
-

- Closed
-
- relates to
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
Activity
bzhaoopenstack, thank you.
I remember discussing the dummy barrier
__asm__ __volatile__("" ::: "memory"); |
with some people in the past, possibly svoj who was working on ARMv8 optimizations (MDEV-14442). If I remember correctly, the conclusion was that this statement has two effects:
- Invalidate the ‘cache’ that the compiler maintains by possibly keeping some memory-based variables in registers. Registers should be written back before this statement.
- Prevent an otherwise empty loop from being optimized away.
Starting with MariaDB Server 10.4, where InnoDB uses C++11 std::atomic, the compiler-memory barrier should not be necessary. (But, there is also some code that uses the C wrapper functions my_atomic_ where the barrier may be necessary.)
So, the main effect of the statement should be to prevent the ut_delay() loop from being optimized away.
In MDEV-23633, krunalbauskar was referring to MDEV-23399 and MDEV-23855, which were affecting write-heavy benchmarks. He has also blogged about the atomics changes in Large System Extensions.
I see that the -moutline-atomics flag was already added to MariaDB (10.4.14, 10.5.5).
So, the outstanding issue is whether the isb instruction would be beneficial. I think that the impact should be demonstrated with benchmarking.
Please note that the 10.4, 10.5, and 10.6 branches are expected to perform rather differently. In the latest 10.5, the buf_pool.page_hash uses a lighter-weight rw_lock implementation (MDEV-22871) and some mutexes (such as buf_pool.mutex) were replaced with standard ones, so that the spinloop is executed less frequently.
In 10.6, all mutexes were replaced with standard ones (MDEV-21452) and all rw_lock_t were replaced as well (MDEV-24142, MDEV-24167). For the new srw_lock and ssux_lock, different implementations are available. With all implementations, at least buf_pool.page_hash, dict_index_t::lock, buf_block_t::lock will execute a spinloop that is based on ut_delay().
For demonstrating the impact of the proposed change, I would like to see benchmark results especially on the latest 10.6 development snapshot. There is still one caveat that I am currently working on. Until MDEV-20612 has been fixed, in write benchmarks the contention on lock_sys.mutex will cause performance degradation. That issue should not be encountered in read-only benchmarks. A read-only benchmark with a small buffer pool (so that the data will not fit) should exercise the rw-lock spin loops.
Marko,
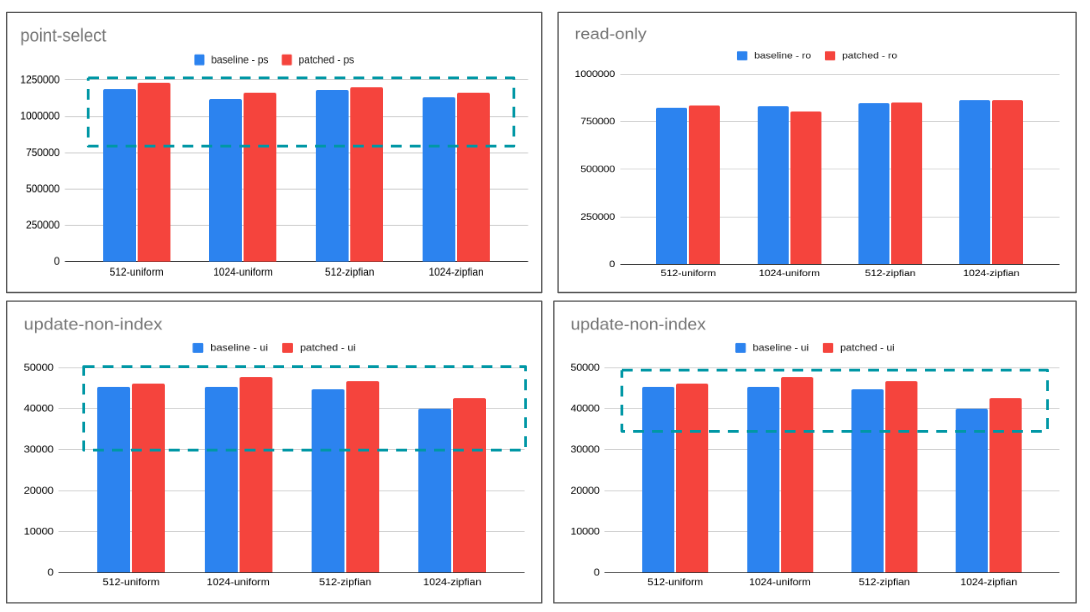
I tried to benchmark <isb> approach. 10.5 the said patch helps across the board. 10.6 results are mixed so I would not suggest it to be applied for 10.6 but only limit it to 10.5.
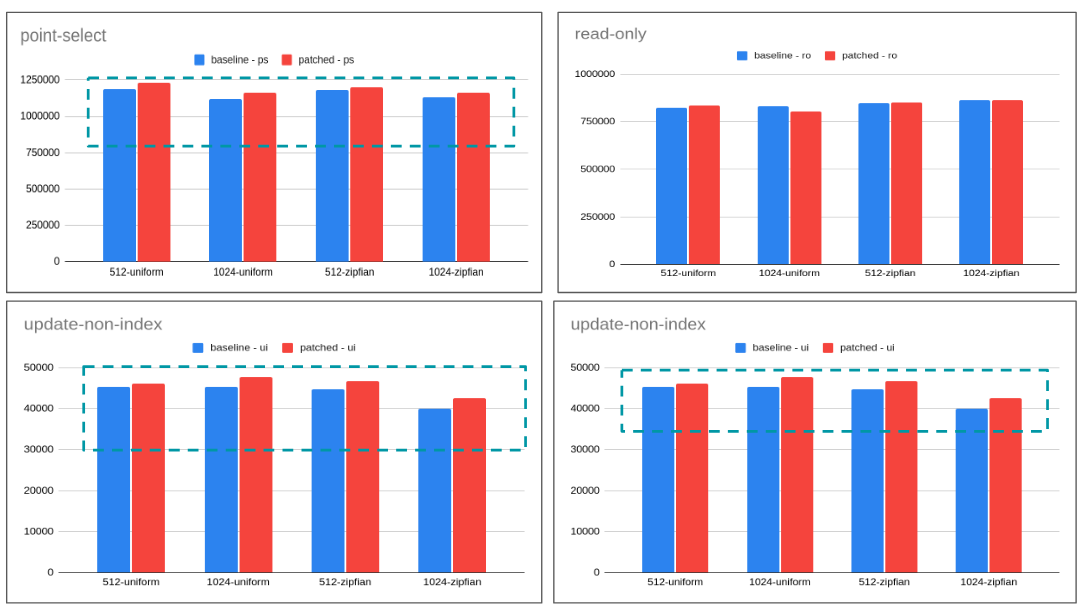
krunalbauskar, thank you. I am happy to merge any pull request that is guaranteed to have no impact on other architectures than ARM, to any branch. If some change is specific to 10.5 only, then I would like to see the 10.6 version at the same time, to help with merging.
If a change might potentially affect the AMD64 ISA, then the performance impact would have to be tested carefully. At MariaDB, we only have AMD64 based hardware for running benchmarks.
bzhaoopenstack, krunalbauskar, is there a more specific define for where isb exists? Debian wants to revert this because of an armhf failure - https://salsa.debian.org/mariadb-team/mariadb-10.5/-/blob/master/debian/patches/revert-isb-assembly-instruction.patch#L1
Daniel,
Seems like debian has support for 3 different arm machine and probably one which is failing is a pretty old version which doesn't support the said instruction.
So we can make it specific to _aarch64_ (as per the arm official reference manual ISB should be defined by all ARMv8 processors).
[as per the ARMv7 specs even 32 bits processor should support it but not sure which exact version Debian has under armel].
In either case, the said performance issue will have an impact mainly with a high-end processors with extreme parallelism so it safe to limit it to _aarch64_.
Do let me know if we should submit the patch or you can direct make the changes.
=============================================================
#elif defined _GNUC_ && (defined _arm_ || defined _aarch64_)
/* Mainly, prevent the compiler from optimizing away delay loops */
+#ifdef _aarch64_
_asm_ _volatile_ ("isb":::"memory");
+#else
+ /* some older 32 bits processor doesn't support isb but as per
+ arm-v8 reference manual all armv8 processor should support isb. */
+ _asm_ _volatile_ ("":::"memory");
+#endif
#else
=============================================================
<debian>
Debian/armel targets older 32-bit ARM processors without support for a hardware floating point unit (FPU),
Debian/armhf works only on newer 32-bit ARM processors which implement at least the ARMv7 architecture with version 3 of the ARM vector floating point specification (VFPv3). It makes use of the extended features and performance enhancements available on these models.
Debian/arm64 works on 64-bit ARM processors which implement at least the ARMv8 architecture.
</debian>
FYI, I've created MDEV-25807 that explains my proposed fix. This should be easy to set up with a CMake check, but I need some time to be able to reproduce it on the older ARM cpu.
"isb" is an odd choice and it throws a bunch of work to neighbouring CPUS to do work to delay the current thread. This would seem harmful in the way CAS was.